
Upgrade Your Drupal Skills
We trained 1,000+ Drupal Developers over the last decade.
See Advanced Courses NAH, I know EnoughCoincidence?
We're ready to celebrate and build (even more) amazing Drupal 8 websites.
On November 19 we'll put our Drupal 8 websites in the spotlight...be sure to come back and check out our website.
By
Michèle WeiszShare


Want to know more?
Contact us todayor call us +32 (0)3 298 69 98
© 2015 Wunderkraut Benelux
Drupalcon 2015
People from across the globe who use, develop, design and support the Drupal platform will be brought together during a full week dedicated to networking, Drupal 8 and sharing and growing Drupal skills.
As we have active hiring plans we’ve decided that this year’s approach should have a focus on meeting people who might want to work for Wunderkraut and getting Drupal 8 out into the world.
As Signature Supporting Partner we wanted as much people as possible to attend the event. We managed to get 77 Wunderkrauts on the plane to Barcelona! From Belgium alone we have an attendance of 17 people.
The majority of our developers will be participating in sprints (a get-together for focused development work on a Drupal project) giving all they got together with all other contributors at DrupalCon.
We look forward to an active DrupalCon week.
If you're at DrupalCon and feel like talking to us. Just look for the folks with Wunderkraut carrot t-shirts or give Jo a call at his cell phone +32 476 945 176.
Share
Related Blog Posts
Want to know more?
Contact us todayor call us +32 (0)3 298 69 98
© 2015 Wunderkraut Benelux
How Wunderkraut feels about Drupal 8
Drupal 8 is coming and everyone is sprinting hard to get it over the finish line. To boost contributor morale we’ve made a motivational Drupal 8 video that will get them into the zone and tackling those last critical issues in no time.
[embedded content]
Share
Related Blog Posts
Want to know more?
Contact us todayor call us +32 (0)3 298 69 98
© 2015 Wunderkraut Benelux
Once again Heritage day was a huge succes.
About 400 000 visitors visited Flanders monuments and heritage sites last Sunday. The Open Monumentendag website received more than double the amount of last year's visitors.
Visitors to the website organised their day out by using the powerful search tool we built that allowed them to search for activities and sights at their desired location. Not only could they search by location (province, zip code, city name, km range) but also by activity type, keywords, category and accessibility. Each search request being added as a (removable) filter for finding the perfect activity.
By clicking on the heart icon, next to each activity, a favorite list was drawn up. Ready for printing and taking along as route map.
Our support team monitored the website making sure visitors had a great digital experience for a good start to the day's activities.
Did you experience the ease of use of the Open Monumentendag website? Are you curious about the know-how we applied for this project? Read our Open Monumentendag case.
Breaking ground as Drupal's first Signature Supporting Partner
Drupal Association Executive Director Holly Ross is thrilled that Wunderkraut is joining as first and says: "Their support for the Association and the project is, and has always been, top-notch. This is another great expression of how much Wunderkraut believes in the incredible work our community does."
As Drupal Signature Supporting Partner we commit ourselves to advancing the Drupal project and empowering the Drupal community. We're very proud to be a part of it as we enjoy contributing to the Drupal ecosystem (especially when we can be quircky and fun as CEO Vesa Palmu states).
Our contribution allowed the Drupal Association to:
- Complete Drupal.org's D7 upgrade - now they can enhance new features
- Hired a full engineering team committed to improving Drupal.org infrastructure
- Set the roadmap for Drupal.org success.

By
Michèle WeiszShare
Related Blog Posts
Want to know more?
Contact us todayor call us +32 (0)3 298 69 98
© 2015 Wunderkraut Benelux
But in this post I'd like to talk about one of the disadvantages that here at Wunderkraut we pay close attention to.
A consequence of the ability to build features in more than one way is that it's difficult to predict how different people interact (or want to interact) with them. As a result, companies end up delivering solutions to their clients that although seem perfect, turn out, in time, to be less than ideal and sometimes outright counterproductive.
Great communication with the client and interest in their problems goes a long way towards minimising this effect. But sometimes clients realise that certain implementations are not perfect and could be made better. And when that happens, we are there to listen, adapt and reshape future solutions by taking into account these experiences.
One such recent example involved the use of a certain WYSIWYG library from our toolkit on a client website. Content editors were initially happy with the implementation before they actually started using it to the full extent. Problems began to emerge, leading to editors spending way more time than they should have performing editing tasks. The client signalled this problem to us which we then proceed to correct by replacing said library. This resulted in our client becoming happier with the solution, much more productive and less frustrated with their experience on their site.
We learned an important lesson in this process and we started using that new library on other sites as well. Polling our other clients on the performance of the new library revealed that indeed it was a good change to make.
A few years ago most of the requests started with : "Dear Wunderkraut, we want to build a new website and ... " - nowadays we are addressed as "Dear Wunderkraut, we have x websites in Drupal and are very happy with that, but we are now looking for a reliable partner to support & host ... ".
By the year 2011 Drupal had been around for just about 10 years. It was growing and changing at a fast pace. More and more websites were being built with it. Increasing numbers of people were requesting help and support with their website. And though there were a number of companies flourishing in Drupal business, few considered specific Drupal support an interesting market segment. Throughout 2011 Wunderkraut Benelux (formerly known as Krimson) was tinkering with the idea of offering support, but it was only when Drupal newbie Jurgen Verhasselt arrived at the company in 2012 that the idea really took shape.
Before his arrival, six different people, all with different profiles, were handling customer support in a weekly rotation system. This worked poorly. A developer trying to get his own job done plus deal with a customer issue at the same time was getting neither job done properly. Tickets got lost or forgotten, customers felt frustrated and problems were not always fixed. We knew we could do better. The job required uninterrupted dedication and constant follow-up.
That’s where Jurgen came in the picture. After years of day job experience in the graphic sector and nights spent on Drupal he came to work at Wunderkraut and seized the opportunity to dedicate himself entirely to Drupal support. Within a couple of weeks his coworkers had handed over all their cases. They were relieved, he was excited! And most importantly, our customers were being assisted on a constant and reliable basis.
By the end of 2012 the first important change was brought about, i.e. to have Jurgen work closely with colleague Stijn Vanden Brande, our Sys Admin. This team of two ensured that many of the problems that arose could be solved extremely efficiently. Wunderkraut being the hosting party as well as the Drupal party means that no needless discussions with the hosting took place and moreover, the hosting environment was well-known. This meant we could find solutions with little loss of time, as we know that time is an important factor when a customer is under pressure to deliver.
In the course of 2013 our support system went from a well-meaning but improvised attempt to help customers in need to a fully qualified division within our company. What changed? We decided to classify customer support issues into: questions, incidents/problems and change requests and incorporated ITIL based best practices. In this way we created a dedicated Service Desk which acts as a Single Point of Contact after Warranty. This enabled us to offer clearly differing support models based on the diverse needs of our customers (more details about this here). In addition, we adopted customer support software and industry standard monitoring tools. We’ve been improving ever since, thanks to the large amount of input we receive from our trusted customers. Since 2013, Danny and Tim have joined our superb support squad and we’re looking to grow more in the months to come.
When customers call us for support we do quite a bit more than just fix the problem at hand. Foremostly, we listen carefully and double check everything to ensure that we understand him or her correctly. This helps to take the edge off the huge pressure our customer may be experiencing. After which, we have a list of do’s and don’t for valuable support.
- Do a quick scan of possible causes by getting a clear understanding of the symptoms
- Do look for the cause of course, but also assess possible quick-fixes and workarounds to give yourself time to solve the underlying issue
- Do check if it’s a pebkac
- and finally, do test everything within the realm of reason.
The most basic don’t that we swear by is:
- never, ever apply changes to the foundation of a project.
- Support never covers a problem that takes more than two days to fix. At that point we escalate to development.
We are so dedicated to offering superior support to customers that on explicit request, we cater to our customers’ customers. Needless to say, our commitment in support has yielded remarkable results and plenty of customer satisfaction (which makes us happy, too)
If your website is running Drupal 6, chances are it’s between 3 and 6 years old now, and once Drupal 8 comes out. Support for Drupal 6 will drop. Luckily the support window has recently been prolonged for another 3 months after Drupal 8 comes out. But still, that leaves you only a small window of time to migrate to the latest and greatest. But why would you?
There are many great things about Drupal 8 that will have something for everyone to love, but that should not be the only reason why you would need an upgrade. It is not the tool itself that will magically improve the traffic to your site, neither convert its users to start buying more stuff, it’s how you use the tool.
So if your site is running Drupal 6 and hasn’t had large improvements in the last years it might be time to investigate if it needs a major overhaul to be up to par with the competition. If that’s the case, think about brand, concept, design, UX and all of that first to understand how your site should work and what it should look like, only then we can understand if a choice needs to be made to go for Drupal 7 or Drupal 8.
If your site is still running well you might not even need to upgrade! Although community support for Drupal 6 will end a few months after Drupal 8 release, we will continue to support Drupal 6 sites and work with you to fix any security issues we encounter and collaborate with the Drupal Security Team to provide patches.
My rule of thumb is that if your site uses only core Drupal and a small set of contributed modules, it’s ok to build a new website on Drupal 8 once it comes out. But if you have a complex website running on many contributed and custom modules it might be better to wait a few months maybe a year until all becomes stable.
So how does customer journey mapping work?
In this somewhat simplified example, we map the customer journey of somebody signing up for an online course. If you want to follow along with your own use case, pick an important target audience and a customer journey that you know is problematic for the customer.
1. Plot the customer steps in the journey

Write down the series of steps a client takes to complete this journey. For example “requests brochure”, “receives brochure”, “visits the website for more information”, etc. Put each step on a coloured sticky note.
2. Define the interactions with your organisation

Next, for each step, determine which people and groups the customer interacts with, like the marketing department, copywriter and designer, customer service agent, etc. Do the same for all objects and systems that the client encounters, like the brochure, website and email messages. You’ve now mapped out all people, groups, systems and objects that the customer interacts with during this particular journey.
3. Draw the line

Draw a line under the sticky notes. Everything above the line is “on stage”, visible to your customers.
4. Map what happens behind the curtains

Now we’ll plot the backstage parts. Use sticky notes of a different color and collect the persons, groups, actions, objects and systems that support the on stage part of the journey. In this example these would be the marketing team that produces the prod brochure, the printer, the mail delivery partner, web site content team, IT departments, etc. This backstage part is usually more complex than the on stage part.
5. How do people feel about this?

Now we get to the crucial part. Mark the parts that work well from the perspective of the person interacting with it with green dots. Mark the parts where people start to feel unhappy with yellow dots. Mark the parts where people get really frustrated with red. What you’ll probably see now is that your client starts to feel unhappy much sooner than employees or partners. It could well be that on the inside people are perfectly happy with how things work while the customer gets frustrated.
What does this give you?
Through this process you can immediately start discovering and solving customer experience issues because you now have:
- A user centred perspective on your entire service/product offering
- A good view on opportunities for innovation and improvement
- Clarity about which parts of the organisation can be made responsible to produce those improvements
- In a shareable format that is easy to understand
Mapping your customer journey is an important first step towards customer centred thinking and acting. The challenge is learning to see things from your customers perspective and that's exactly what a customer journey map enables you to do. Based on the opportunities you identified from the customer journey map, you’ll want to start integrating the multitude of digital channels, tools and technology already in use into a cohesive platform. In short: A platform for digital experience management! That's our topic for our next post.
In combination with the FacetAPI module, which allows you to easily configure a block or a pane with facet links, we created a page displaying search results containing contact type content and a facets block on the left hand side to narrow down those results.
One of the struggles with FacetAPI are the URLs of the individual facets. While Drupal turns the ugly GET 'q' parameter into a clean URLs, FacetAPI just concatenates any extra query parameters which leads to Real Ugly Paths. The FacetAPI Pretty Paths module tries to change that by rewriting those into human friendly URLs.
Our challenge involved altering the paths generated by the facets, but with a slight twist.
Due to the projects architecture, we were forced to replace the full view mode of a node of the bundle type "contact" with a single search result based on the nid of the visited node. This was a cheap way to avoid duplicating functionality and wasting precious time. We used the CTools custom page manager to take over the node/% page and added a variant which is triggered by a selection rule based on the bundle type. The variant itself doesn't use the panels renderer but redirects the visitor to the Solr page passing the nid as an extra argument with the URL. This resulted in a path like this: /contacts?contact=1234.
With this snippet, the contact query parameter is passed to Solr which yields the exact result we need.
/**
* Implements hook_apachesolr_query_alter().
*/
function myproject_apachesolr_query_alter($query) {
if (!empty($_GET['contact'])) {
$query->addFilter('entity_id', $_GET['contact']);
}
}
The result page with our single search result still contains facets in a sidebar. Moreover, the URLs of those facets looked like this: /contacts?contact=1234&f[0]=im_field_myfield..... Now we faced a new problem. The ?contact=1234 part was conflicting with the rest of the search query. This resulted in an empty result page, whenever our single search result, node 1234, didn't match with the rest of the search query! So, we had to alter the paths of the individual facets, to make them look like this: /contacts?f[0]=im_field_myfield.
This is how I approached the problem.
If you look carefully in the API documentation, you won't find any hooks that allow you to directly alter the URLs of the facets. Gutting the FacetAPI module is quite daunting. I started looking for undocumented hooks, but quickly abandoned that approach. Then, I realised that FacetAPI Pretty Paths actually does what we wanted: alter the paths of the facets to make them look, well, pretty! I just had to figure out how it worked and emulate its behaviour in our own module.
Turns out that most of the facet generating functionality is contained in a set of adaptable, loosely coupled, extensible classes registered as CTools plugin handlers. Great! This means that I just had to find the relevant class and override those methods with our custom logic while extending.
Facet URLs are generated by classes extending the abstract FacetapiUrlProcessor class. The FacetapiUrlProcessorStandard extends and implements the base class and already does all of the heavy lifting, so I decided to take it from there. I just had to create a new class, implement the right methods and register it as a plugin. In the folder of my custom module, I created a new folder plugins/facetapi containing a new file called url_processor_myproject.inc. This is my class:
/**
* @file
* A custom URL processor for cancer.
*/
/**
* Extension of FacetapiUrlProcessor.
*/
class FacetapiUrlProcessorMyProject extends FacetapiUrlProcessorStandard {
/**
* Overrides FacetapiUrlProcessorStandard::normalizeParams().
*
* Strips the "q" and "page" variables from the params array.
* Custom: Strips the 'contact' variable from the params array too
*/
public function normalizeParams(array $params, $filter_key = 'f') {
return drupal_get_query_parameters($params, array('q', 'page', 'contact'));
}
}
I registered my new URL Processor by implementing hook_facetapi_url_processors in the myproject.module file.
**
* Implements hook_facetapi_url_processors().
*/
function myproject_facetapi_url_processors() {
return array(
'myproject' => array(
'handler' => array(
'label' => t('MyProject'),
'class' => 'FacetapiUrlProcessorMyProject',
),
),
);
}
I also included the .inc file in the myproject.info file:
files[] = plugins/facetapi/url_processor_myproject.inc
Now I had a new registered URL Processor handler. But I still needed to hook it up with the correct Solr searcher on which the FacetAPI relies to generate facets. hook_facetapi_searcher_info_alter allows you to override the searcher definition and tell the searcher to use your new custom URL processor rather than the standard URL processor. This is the implementation in myproject.module:
/**
* Implements hook_facetapi_search_info().
*/
function myproject_facetapi_searcher_info_alter(array &$searcher_info) {
foreach ($searcher_info as &$info) {
$info['url processor'] = 'myproject';
}
}
After clearing the cache, the correct path was generated per facet. Great! Of course, the paths still don't look pretty and contain those way too visible and way too ugly query parameters. We could enable the FacetAPI Pretty Path module, but by implementing our own URL processor, FacetAPI Pretty Paths will cause a conflict since the searcher uses either one or the other class. Not both. One way to solve this problem would be to extend the FacetapiUrlProcessorPrettyPaths class, since it is derived from the same FacetapiUrlProcessorStandard base class, and override its normalizeParams() method.
But that's another story.
What is a views display extender
The display extender plugin allow to add additional options or configuration to a views regardless of the type of display (e.g. page, block, ..).
For example, if you wanted to allow site users to add certain metadata to the rendered output of every view display regardless of display type, you could provide this option as a display extender.
What we can do with it
We will see how we implement such a plugin, for the example, we will add some metadata (useless metatags as example) to the document head when the views is displayed.
We will call the display extender plugin HeadMetadata (id: head_metadata) and we will implement it in a module called views_head_metadata.
The implementation
Make our plugin discoverable
Views do not discover display extender plugins with a hook info as usual, for this particular type of plugin, views has a variable in his views.settings configuration object.
You need to add your plugin ID to the variable views.settings.display_extenders (that is a list).
To do so, I will recommend you to implement the hook_install (as well uninstall) in the module install file. To manipulate config object you can look at my previous notes on CMI.
Make the plugin class
As seen in the previous post on Drupal 8 plugins, you need to implement the class in the plugin type namespace, extend the base class for this type of plugin, and add the metadata annotation.
In the case of the display extender plugin, the namespace is Drupal\views_head_metadata\Plugin\views\display_extender, the base class is DisplayExtenderPluginBase, and the metadata annotation are defined in \Drupal\views\Annotation\ViewsDisplayExtender.
The display extender plugins methods are nearly the same that the display plugins, you can think of its like a set of methods to alter the display plugin.
The important methods to understand are :
- defineOptionsAlter(&$options) : Define an array of options your plugins will define and save. Sort of schema of your plugin.
- optionsSummary(&$categories, &$options) : To add a category (the section of the views admin interface) if you want to add one, and define your options settings (in wich category there are, and the value to display as the summary).
- buildOptionsForm(&$form, FormStateInterface $form_state) : Where you construct the form(s) for your plugin, of course linked with a validate and submit method.
Generate the metadata tags in the document head
Now that we have our settings added to every views display, we need to use those to generate the tags in the document head as promised.
To work on the views render we will use the hook for that : hook_views_pre_render($view) and the render array property #attached.
Implement that hook in the .module of our module views_head_metadata, let's see :
For the example we are going to implement an area that will present some links and text in a custom way, not sure if it's really usefull, but that not the point of this article.
The Plugin system
For the first post on the plugins I will introduce briefly on the concept. For those that already been using Ctools plugins system, you already now about the plugin system purposes.
For those who doesn't know about it, the plugin system is a way to let other module implements her own use case for an existing features, think of Field formatter : provide your own render array for a particular field display, or Widget : provide your own form element for a particular field type, etc...
The plugin system has three base elements :
Plugin Types
The plugin type is the central controlling class that defines how the plugins of this type will be discovered and instantiated. The type will describe the central purpose of all plugins of that type; e.g. cache backends, image actions, blocks, etc.
Plugin Discovery
Plugin Discovery is the process of finding plugins within the available code base that qualify for use within this particular plugin type's use case.
Plugin Factory
The Factory is responsible for instantiating the specific plugin(s) chosen for a given use case.
Detailled informations : https://www.drupal.org/node/1637730
In our case Views is responsible of that implementations so we are not going further on that, let see now how to implement a plugin definition.
The Plugin definitions
The existing documentation on the plugin definitions are a little abstract for now to understand how it really works (https://www.drupal.org/node/1653532).
You have to understand simply that a Plugin in most case is a Class implementation, namespaced within the namespace of the plugin type, in our example this is : \Drupal\module_name\Plugin\views\area
So if I implement a custom views area Plugin in my module the class will be located under the location module_name/src/Plugin/views/area/MyAreaHandler.php
To know where to implement a plugin definition for a plugin type, you can in most case look at module docs, or directly in the source code of the module (looking at an example of a definition will be enough)
In most cases, the modules that implement a Plugin type will provide a base class for the plugins definitions, in our example views area provide a base class : \Drupal\views\Plugin\views\area\AreaPluginBase
Drupal provide also a base class, if you implement a custom Plugin type, for the Plugin definition : \Drupal\Component\Plugin\PluginBase
Your custom plugin definition class must also have annotation metadata, that is defined by the module that implement the plugin type, in our example : \Drupal\views\Annotation\ViewsArea
In the case of views you will also need to implement the hook_views_data() into module_name.views.inc file, there you will inform views about the name and metadata of your Area handler.
Hands on implementation
So we have a custom module let's call it module_name for the example :)
We will create the class that implements our plugin definition and we are gonna give it this Plugin ID : my_custom_site_area.
We save this file into module_name/src/Plugin/views/area/MyCustomSiteArea.php
Now we just have to implements the hook_views_data() and yes this is the end, you can use your awesome views area handler into any view and any area.
Define this hook into the file : module_name/module_name.views.inc
There is three types of configuration data :
The Simple Configuration API
-
Used to store unique configuration object.
-
Are namespaced by the module_name.
-
Can contain a list of structured variables (string, int, array, ..)
-
Default values can be found in Yaml : config/install/module_name.config_object_name.yml
-
Have a schema defined in config/schema/module_name.schema.yml
Code example :
The States
-
Not exportable, simple value that hardly depend of the environment.
-
Value can differ between environment (e.g. last_cron, maintenance_mode have different value on your local and on the production site)
The Entity Configuration API
-
Configuration object that can be multiple (e.g. views, image style, ckeditor profile, ...).
-
New Configuration type can be defined in custom module.
-
Have a defined schema in Yaml.
-
Not fieldable.
-
Values can be exported and stored as Yaml, can be stored by modules in config/install
Code example :
https://www.drupal.org/node/1809494
Store configuration object in the module :
Config object (not states) can be stored in a module and imported during the install process of the modules.
To export a config object in a module you can use the configuration synchronisation UI at /admin/config/development/configuration/single/export
Select the configuration object type, then the object, copy the content and store it in your custom module config/install directory following the name convention that is provided below the textarea.
You can also use the features module that is now a simple configuration packager.
If after the install of the module, you want to update the config object, you can use the following drush command :
Configuration override system
Remember the variable $conf in settings.php in D6/D7 for overriding variables.
In D8, you can also override variable from the configuration API:
You can also do overrides at runtime.
Example: getting a value in a specific languages :
Drupal provide a storage for override an module can specify her own way of override, for deeper informations look at :
https://www.drupal.org/node/1928898
Configuration schema
The config object of Config API and of the configuration entity API have attached schema defined in module_name/config/install/module_name.schema.yml
These schema are not mandatory, but if you want to have translatable strings, nor form configuration / consistent export, you must take the time to implement the schema for your configuration object. However if you don't want to, you can just implement the toArray() method in your entity config object class.
Example, docs and informations : https://www.drupal.org/node/1905070
Configuration dependencies calculation
Default is in the .info of the module that define the config object like in D6/D7
But config entity can implements calculateDependencies() method to provide dynamic dependencies depending on config entity values.
Think of Config entity that store field display information for content entities specific view modes, there a need to have the module that hold the fields / formatters in dependencies but these are dynamic depending on the content entity display.
More information : https://www.drupal.org/node/2235409
Ressources
Migrate in Drupal 8
Migrate is now included in the Drupal core for making the upgrade path from 6.x and 7.x versions to Drupal 8.
Drupal 8 has two new modules :
Migrate: « Handles migrations »
Migrate Drupal : « Contains migrations from older Drupal versions. »
None of these module have a User Interface.
« Migrate » contains the core framework classes, the destination, source and process plugins schemas and definitions, and at last the migration config entity schema and definition.
« Migrate Drupal » contains implementations of destination, sources and process plugins for Drupal 6 and 7 you can use it or extend it, it's ready to use. But this module doesn't contain the configuration to migrate all you datas from your older Drupal site to Drupal 8.
The core provides templates of migration configuration entity that are located under each module of the core that needs one, under a folder named 'migration_templates' to find all the templates you can use this command in your Drupal 8 site:
To make a Drupal core to core migration, you will find all the infos here : https://www.Drupal.org/node/2257723 there is an UI in progress for upgrading.
A migration framework
Let have a look at each big piece of the migration framework :
Source plugins
Drupal provides an interface and base classes for the migration source plugin :
- SqlBase : Base class for SQL source, you need to extend this class to use it in your migration.
- SourcePluginBase : Base class for every custom source plugin.
- MenuLink: For D6/D7 menu links.
- EmptySource (id:empty): Plugin source that returns an empty row.
- ...
Process plugins
There is the equivalent of the D7 MigrateFieldHandler but this is not reduced to fields or to a particular field type.
Its purpose is to transform a raw value into something acceptable by your new site schema.
The method transform() of the plugin is in charge of transforming your $value or skipping the entire row if needed.
If the source property has multiple values, the transform() will happen on each one.
Drupal provides migration process plugin into each module of the core that needs it (for the core upgrade),
To find out which one and where it is located you can use this command :
Destination plugins
Destination plugins are the classes that handle where your data are saved in the new Drupal 8 sites schemas.
Drupal provides a lot of useful destination classes :
- DestinationBase : Base class for migrate destination classes.
- Entity (id: entity) : Base class for entity destinations.
- Config (id: config) : Class for importing configuration entities.
- EntityBaseFieldOverride (id: entity:base_field_override): Class for importing base field.
- EntityConfigBase : Base class for importing configuration entities.
- EntityImageStyle (id: entity:image_style): Class for importing image_style.
- EntityContentBase (id: entity:%entity_type): The destination class for all content entities lacking a specific class.
- EntityNodeType: (id: entity:node_type): A class for migrate node type.
- EntityFile (id: entity:file): Class for migrate files.
- EntityFieldInstance: Class for migrate field instance.
- EntityFieldStorageConfig: Class for migrate field storage.
- EntityRevision, EntityViewMode, EntityUser, Book...
- And so more…
Builder plugins:
"Builder plugins implement custom logic to generate migration entities from migration templates. For example, a migration may need to be customized based on the data that is present in the source database; such customization is implemented by builders." - doc API
This is used in the user module, the builder create a migration configuration entity based on a migration template and then add fields mapping to the process, based on the data in the source database. (@see /Drupal/user/Plugin/migrate/builder/d7/User)
Id map plugins:
"It creates one map and one message table per migration entity to store the relevant information." - doc API
This is where rollback, update and the map creation are handled.
Drupal provides the Sql plugin (@see /Drupal/migrate/Plugin/migrate/id_map/Sql) based on the core base class PluginBase.
And we are talking only about core from the beginning.
All the examples (That means docs for devs) are in core !
About now :
While there *almost* a simple UI to use migration in Drupal 8 for Drupal to Drupal, Migrate can be used for every kind of data input. The work is in progess for http://Drupal.org/project/migrate_plus to bring an UI and more source plugins, process plugins and examples. There already is the CSV source plugin and a pending patch for the code example. The primary goal of « migrate plus » is to have all the features (UI, Sources, Destinations.. ) of the Drupal 7 version.
Concrete migration
(migration with Drupal 8 are made easy)
I need to migrate some content with image, attached files and categories from custom tables in an external SQL database to Drupal.
To begin shortly :
- Drush 8 (dev master) and console installed.
- Create the custom module (in the code, I assume the module name is “example_migrate”):
$ Drupal generate:module
or create the module by yourself, you only need the info.yml file. - Activate migrate and migrate_plus tools
$ Drupal module:install migrate_tools
or
$ drush en migrate_tools - What we have in Drupal for the code example :
- a taxonomy vocabulary : ‘example_content_category’
- a content type ‘article’
- some fields: body, field_image, field_attached_files, field_category
- Define in settings.php, the connexion to your external database:
We are going to tell migrate source to use this database target. It happens in each migration configuration file, it’s a configuration property used by the SqlBase source plugin:
This is one of the reasons SqlBase has a wrapper for select query and you need to call it in your source plugin, like $this->select(), instead of building the query with bare hands.
N.B. Each time you add a custom yml file in your custom module you need to uninstall/reinstall the module for the config/install files to imports. In order to avoid that, you can import a single migration config file by copy/paste in the admin/config configuration synchronisation section.
The File migration
The content has images and files to migrate, I suppose in this example that the source database has a unique id for each file in a specific table that hold the file path to migrate.
We need a migration for the file to a Drupal 8 file entity, we write the source plugin for the file migration:
File: src/Plugin/migrate/source/ExampleFile.php
We have the source class and our source fields and each row generate a path to the file on my local disk.
But we need to transform our external file path to a local Drupal public file system URI, for that we need a process plugin. In our case the process plugin will take the external filepath and filename as arguments and return the new Drupal URI.
File: src/Plugin/migrate/process/ExampleFileUri.php
We need another process plugin to transform our source date values to timestamp (created, changed), as the date format is the same across the source database, this plugin will be reused in the content migration for the same purpose:
File: src/Plugin/migrate/process/ExampleDate.php
For the destination we use the core plugin: entity:file.
Now we have to define our migration config entity file, this is where the source, destination and process (field mappings) are defined:
File: config/install/migrate.migration.example_file.yml
We are done for the file migration, you can execute it with the migrate_tools (of the migrate_plus project) drush command:
The Term migration
The content has categories to migrate.
We need to import them as taxonomy term, in this example I suppose the categories didn't have unique ids, it is just a column of the article table with the category name…
First we create the source :
File: src/Plugin/migrate/source/ExampleCategory.php
And we can now create the migration config entity file :
File: config/install/migrate.migration.example_category.yml
This is done, to execute it :
The Content migration
The content from the source has an html content, raw excerpt, image, attached files, categories and the creation/updated date in the format Y-m-d H:i:s
We create the source plugin:
File: src/Plugin/migrate/source/ExampleContent.php
Now we can create the content migration config entity file :
File: config/install/migrate.migration.example_content.yml
Finally, execute it :
Group the migration
Thanks to migrate_plus, you can specify a migration group for your migration.
You need a to create a config entity for that :
File: config/install/migrate_plus.migration_group.example.yml
Then in your migration config yaml file, be sure to have the line migration_group next to the label:
So you can use the command to run the migration together, and the order of execution will depend on the migration dependencies:
I hope that you enjoyed our article.
Best regards,
At Studio.gd we love the Drupal ecosystem and it became very important to us to give back and participate.
Today we're proud to announce a new module that we hope will help you !
Inline Entity Display module will help you handle the display of referenced entity fields directly in the parent entity.
For exemple if you reference a taxomony "Tags" to an Article node, you will be able directly in the manage display of the article to display tags' fields. It can become very usefull with more complex referenced entity like field collection for exemple.
VOIR LE MODULE : https://www.drupal.org/project/inline_entity_display
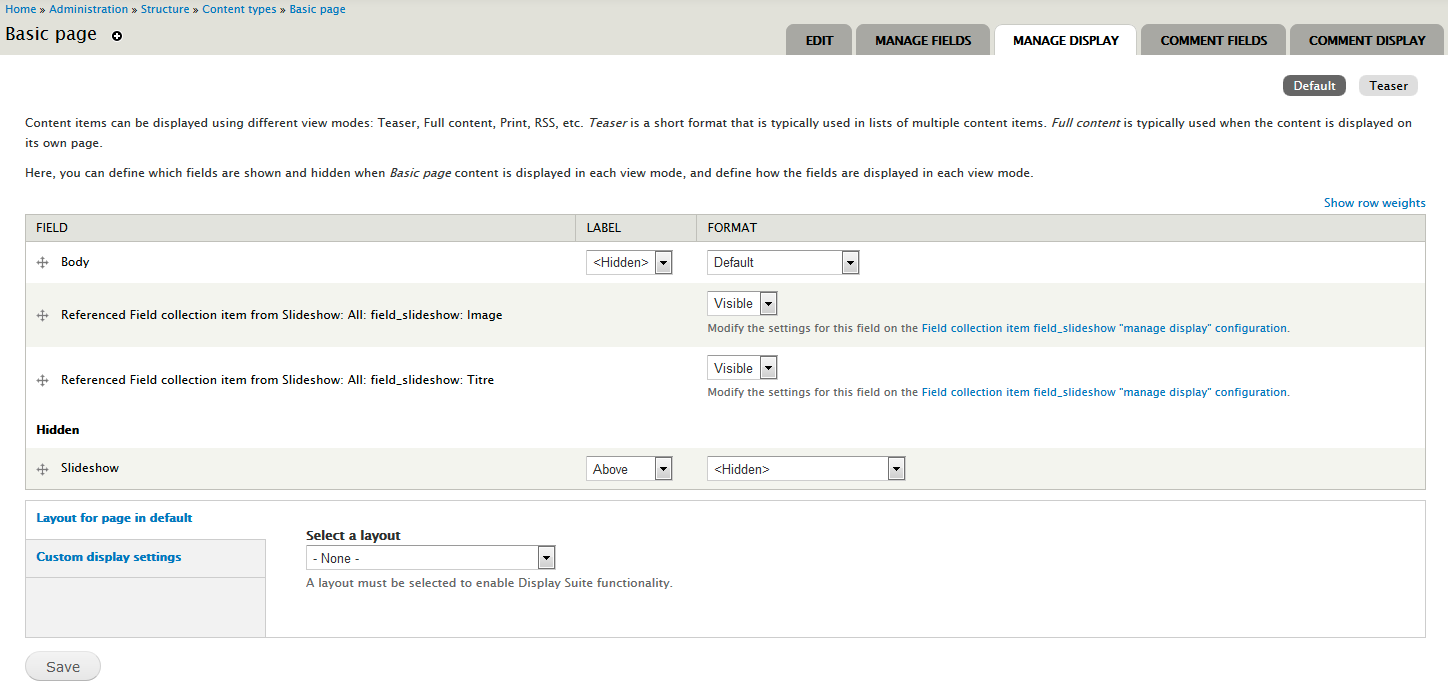
Features
- You can control, for each compatible reference field instances, if the fields from the referenced entities would be available as extra fields. Disabled by default.
- You can manage the visibility of the referenced entities fields on the manage display form. Hidden by default.
- View modes are added to represent this context and manage custom display settings for the referenced entities fields in this context {entity_type}_{view_mode} Example: "Node: Teaser" is used to render referenced entities fields, when you reference an entity into a node, and you view this node as a teaser if there are no custom settings for this view mode, fields are rendered using the default view mode settings.
- Extra data attributes are added on the default fields markup, so the field of the same entity can be identified.
Compatible with Field group on manage display form.
Compatible with Display Suite layouts on manage display form.
Requirements
- Entity API
- One of the compatible reference fields module.
Tutorials
simplytest.me/project/inline_entity_display/7.x-1.x
The simplytest.me install of this module will come automatically with these modules: entity_reference, field_collection, field_group, display suite.
VOIR LE MODULE : https://www.drupal.org/project/inline_entity_display
We are currently developping a similar module for Drupal 8 but more powerful and more flexible, Stay tuned !
Today we are talking about Access Policy API, What it does, and How you can use it with guest Kristiaan Van den Eynde. We’ll also cover Visitors as our module of the week.
For show notes visit:
https://www.talkingDrupal.com/472
Topics
- What is the Access Policy API
- Why does Drupal need the Access Policy API
- How did Drupal handle access before
- How does the Access Policy API interact with roles
- Does a module exist that shows a UI
- What is the difference between Policy Based Access Control (PBAC), Attribute Based Access Control (ABAC) and Role Based Access Control (RBAC)
- How does Access Policy API work with PBAC, ABAC and RBAC
- Can you apply an access policy via a recipe
- Is there a roadmap
- What was it like going through pitchburg
- How can people get involved
Resources
Guests
Kristiaan Van den Eynde - kristiaanvandeneynde
Hosts
Nic Laflin - nLighteneddevelopment.com nicxvan
John Picozzi - epam.com johnpicozzi
Aubrey Sambor - star-shaped.org starshaped
MOTW
Correspondent
Martin Anderson-Clutz - mandclu.com mandclu
- Brief description:
- Have you ever wanted a Drupal-native solution for tracking website visitors and their behavior? There’s a module for that
- Module name/project name:
- Brief history
- How old: created in Mar 2009 by gashev, though recent releases are by Steven Ayers (bluegeek9)
- Versions available: 8.x-2.19, which works with Drupal 10 and 11
- Maintainership
- Actively maintained
- Security coverage
- Test coverage
- Documentation guide is available
- Number of open issues: 20 open issues, none of which are bugs against the 8.x branch
- Usage stats:
- Over 6,000 sites
- Module features and usage
- A benefit of using a Drupal-native solution is that you retain full ownership over your visitor data. Not sharing that data with third parties can be important for data protection regulations, as well as data privacy concerns.
- You also have a variety of reports you can access directly within the Drupal UI, including top pages, referrers, and more
- There is a submodule for geoip lookups using Maxmind, if you also want reporting on what region, country, or city your visitors hail from
- It provides drush commands to download a geoip database, and then update your data based on geoip lookups using that database
- It should be mentioned that the downside of using Drupal as your analytics solution is the potential performance impact and also a likely uptick in usage for hosts that charge based on the number of dynamic requests served

Headless websites have taken the industry by storm, promising to deliver unique brand experiences that enable customer loyalty. Using a headless approach for your project allows you to combine technologies that would normally be siloed due to language or server constraints.
Typically when we talk about a headless Drupal architecture, we are referring to using Drupal for its strength as a content management system (CMS), but using a framework like React or Vue to drive the frontend. This separation of concerns allows your teams to focus on using the tools they know best—ultimately delivering a better product.
The single most important metric in commerce implementations is response time. A website’s overall responsiveness can directly affect the conversion rate and the bottom line. According to a study by Porent in 2019, "The highest e-commerce conversion rates occur between 0 and 2 seconds, spanning an average of 8.11% e-commerce conversion rate at less than 1 second, down to a 2.20% e-commerce conversion rate at a 5 second load time." Let's explore why traditional commerce implementations are so slow and why headless might just be the solution.
Why Use Drupal as a Commerce Platform?
Before we consider the frontend, we need a robust, secure backend platform to deliver our data and business logic. One of the many reasons Drupal is a great candidate for headless, or really any CMS build, is its inherent flexibility and security. Drupal's fieldable entities mean you can structure your CMS to fit your data. Drupal is regularly screened for vulnerabilities and has a robust process to identify and fix security issues. This is especially important in commerce implementations where proprietary data is often pulled from a Product Information Management (PIM) system like Akeneo.
Drupal's true power comes in the form of a massive library of community-contributed and maintained modules. A great example of this is the Drupal Commerce suite maintained by Centarro. Drupal Commerce out-of-the-box provides a robust set of entities and plugins that provide a complete commerce experience. Commerce can be further customized by Contrib modules that provide everything from payment processors (like Stripe or Paypal) to shipping integrations (like UPS or FedEx). Community-contributed modules are the cornerstone of the Drupal platform, and the projects we build make them possible.
Customizing Your Drupal Commerce Forms
Why Is Traditional Commerce Slow?
In a traditional Magento or Drupal Commerce implementation, we often create frontend markup on the backend before delivering the page to the user. As we generate this markup, we make calls to various APIs like shipping rate calculators. Once we have this complete HTML document, we send it to the browser. The browser then parses this markup and scans it for additional documents like CSS, Javascript, and images. Once it gathers all of this data, it turns it into an interactable web page. All of these things make the average page load speed roughly 7 seconds on desktop. That's quite the gap between our target of <2 seconds.
To alleviate the work the backend has to do to render a page, we've come up with some pretty clever tricks. One example is using Edge Side Includes (ESIs). ESIs work by loading the majority of page content from cache, then replacing specific placeholders with dynamic calls to the server. Since the server doesn't need to render the complete markup, we can often achieve faster load times. Drupal Core offers BigPipe, a module that similarly renders the majority of a page from cache, then replaces placeholders with dynamic content. Oftentimes these solutions come at a high complexity and frequently cause problems related to caching. They also don't work for content that is highly dynamic like category pages with facets and filters.
How Does Headless Help?
When we implement a headless website, we can think of the frontend as less like a web page and more as an application. A properly designed React (or other JS frontend framework) app can be lightweight and heavily cacheable. On initial page load, we load our entire application into working memory. This means that as a user navigates through the site, they are actually interacting with a single-page application that does not require a page reload to show new content.
The reason we can get away with not reloading the page is that data can be asynchronously fed to the frontend. This means that as a user is browsing the site we can preload resources like images and linked pages. When we can run expensive operations independently of a user's browsing experience, we can make website response times appear to be instantaneous—or more within our targeted 0-2 second range.
How Do We Get There?
On the backend, you still need a robust, secure CMS to feed data to the frontend and handle complex or session actions (add to cart/checkout validation). This is where Drupal is an easy choice. One of the easiest ways to feed data to a frontend is via JSON data. Drupal Core provides the JSON:API module which allows you to easily expose your content as filterable JSON objects. This means you can leverage the strength of the Drupal Community while giving your frontend room to prefetch and asynchronously validate data.
Building a world-class commerce website necessitates a world-class toolset, but even more so a world-class team. Drupal has proven to be a reliable CMS capable of delivering highly custom experiences. When this is paired with a well-built frontend, load times become instantaneous, and conversion rates increase!
Well, that was exciting! Releasing an enterprise-level Drupal Commerce solution into the wild is a great opportunity to take a moment to reflect: How on earth did we pull that off? This client had multiple stores, multiple product offerings, each with its own requirements for shopping, ordering, payment, and fulfillment flow. And some pretty specific ideas about how the User Experience (UX) was to unfold.
Drupal Commerce offers many possible avenues into the world of customization; here are a few we followed.
Can't I Just Config My Way Out of This?
Yes! But no, probably not. Yes, you should absolutely set up a Proof-of-Concept build using just the tools and configurations at your disposal in the admin user interface (UI). How close did you get? Does your implementation need just a couple of custom fields and a theming, or will it need a ground-up approach? This will help you make more informed estimations of the level of effort and number of story points.
Bundle Up
The Drupal Commerce ecosystem, much like Drupal as a whole, is populated by Entities—fieldable and categorizable into types, or bundles. Think about your particular situation and make use of these categorizations if you can.
Separate your physical and digital products, or your hard goods and textiles. Distinct bundles give you independent fieldsets that you can group with view_displays.
Order Types (admin/commerce/config/order-types/default/edit/fields) are the main organizing principle here: if you have a category of unpaid reservations vs. fully paid orders—that sounds like two separate order_types and two separate checkout flows. Softgoods and hardgoods are tracked for fulfillment in two separate third-party systems? Separate bundles. Keep in mind, though, that a Drupal order is an entity and is a single bundle. An order can have multiple order_item types, but only a single order_type.
Order Item Types (admin/commerce/config/order-item-types/default/edit/fields) bridge the gap between products and orders. Order Item bundles include Purchased Entity, Quantity, and Unit Price by default, but different product categories may need different extra fields on the Add to Cart form.
Adding to Cart
Drupal Commerce offers a path to add Add-to-Cart forms to Product views through the Admin UI.

You could alter the form through the field handler, the formatted, or template of course, but we wanted more direct control and flexibility. We created a route with parameters for product and variation IDs—now we could put the form in a modal and reach it from a CTA placed anywhere. The route's controller, given the product variation, other route parameters, and the page context, decided which order_item_type form to present in the modal.
class PurchasableTextileModalForm extends ModalFormBase {
use AjaxHelperTrait;
/**
* {@inheritdoc}
*/
public function buildForm(array $form, FormStateInterface $form_state, Product $product = NULL, ProductVariation $variation = NULL, $order_type = 'textile', $is_edit_form = FALSE) {
$form = parent::buildForm($form, $form_state, $product, $variation);
...We extended the form from FormBase, incorporated some custom Traits, and used \Drupal\commerce_cart\Form\AddToCartForm as a model. We learned some fun lessons on the way:
- Don't be shy when loading services—who knows what you'll wind up needing.
- Keep in mind that the
form_state'sorder_itemis not the same as thePurchasedEntity. Fields associated with an Order Type are assigned at theform_statelevel, fields on an Order Item bundle are properties of thePurchasedEntity. - Want to check your cart to see if this particular product variation is already a line-item?
\Drupal::service('commerce_cart.order_item_matcher')->match()is your friend. - When validating, recall again that
PurchasedEntityis an Entity, which means it uses the Entity Validation API. TheAvailabilityCheckercomes for free, you may add custom ones simply by registering them inyour_module.services.yml. Or you may want to create a custom Constraint.
Our add-to-cart modal forms (which we reused on the cart view page for editing existing line-items) turned out to be works of art. We had vanilla javascript calculating totals in real-time, we had a service calculating complex allocation data also in real-time, triggered by ajax. Custom widgets saved values to order_item fields which triggered custom Addon OrderProcessors.
class AddonOrderProcessor implements OrderProcessorInterface {
/**
* {@inheritdoc}
*/
public function process(OrderInterface $order) {
foreach ($order->getItems() as $order_item) {
...Recognizing how intricate and interconnected this functionality was going to be, we committed ourselves early on to the necessity of building the forms from scratch.
Wait, What Am I Getting?
The second step of the experience: seeing how full your cart has become after an exuberant shopping session.
Out-of-the-box, Commerce offers a View display at "/cart" of a user's every order item, grouped by order_type.
We wanted separate pages for each order_type, so first we overrode the routing established by commerce_cart and pointed to our own controller which took the order_type as a route parameter.
class RouteSubscriber extends RouteSubscriberBase {
/**
* {@inheritdoc}
*/
protected function alterRoutes(RouteCollection $collection){
// Override "/cart" routing.
if ($route = $collection->get('commerce_cart.page')) {
$route->setDefaults(array(
'_controller' => ...That controller passed the order_type as the display_id argument to the commerce_cart_form view, where we had built out multiple displays.
We had a lot of information to show on the cart page that was not available to the View UI. We had the results of our custom allocation service that we wanted to show in a column with other Purchased Entity information. We had add-on fees we wanted to show in the line item's subtotal column. This stuff wasn't registered as fields associated with an entity in Drupal, these were custom calculations.
We registered custom field handlers that we could select in the Views UI, placing them into columns of the table display and styling them with custom field templates. The render function of these field plugins had access to all the values returned in its ResultRow by the view for our custom calculations:
$values->_relationship_entities['commerce_product_variation']->get('product_id')Let's Transact!
The checkout flow has little customization available off-the-shelf through admin pages. You can reorder the sections on the pages and the Shipping and Tax modules will automatically create panes and sections for you, but otherwise, you get what you get, unless you roll your own.
A custom Checkout Flow starts with a Plugin (so watch your Annotations!) which need not do too much more than define the array of steps. On the other hand, we extended the buildForm() and tucked in a fair amount of alterations, both globally and to specific checkout steps.
Each checkout step can have multiple panes (also plugins: @CommerceCheckoutPane) each with its own form -build, -validate, and -submit functions.
We built custom panes for each step, using shared Traits, extending and reusing existing functionality wherever we could. With a cache clear, our custom panes were available for ordering and placement in the Checkout flow UI.

We managed the order_type-specific fields and collected them in the field_displays tab in the admin UI. We could then easily call for those fields by form_mode in a buildPaneForm() function and render them. We used a similar technique in the validate and submit functions.
$form_display = EntityFormDisplay::collectRenderDisplay($this->order, 'order_reference_detail_checkout');
$form_display->extractFormValues($this->order, $pane_form, $form_state);
$form_display->validateFormValues($this->order, $pane_form, $form_state);Integration Station
This project had a half-dozen in-coming and out-going integration points with outside systems, including customer info, tax and shipping calculator services, the payment gateway, and an order processing service to which the completed order was finally submitted.
Each integration was a separate and idiosyncratic adventure; it would not be terribly enlightening to relate them here. But we are quite sure that, rather than having custom functionality shoe-horned here and there in a number of hook_alters spread over the whole codebase, keeping our checkout forms tidily in individual files and classes helped the development process immeasurably.
And Finally, Ka-ching
The commerce platform space is a landscape crowded with lumbering giants. It was awfully satisfying to see Team Drupal put together a great-looking, custom solution as robust as the big boys, in likely less time and certainly far more tightly integrated with the content, marketing, and SEO side of things. The depth and flexibility that make Drupal such a powerful platform for content management and presentation can also be used to deeply and efficiently customize all aspects of the shopping and checkout experience with Drupal Commerce.

Enterprise organizations are increasingly looking at Drupal as a reliable, open source option for developing their online presence—contributing and benefiting from the active community base and potentially taking advantage of cutting-edge, decoupled capabilities.
With over 10 years of Drupal experience and implementations ranging from small to complex, we are often asked to recommend the best approach for building a Drupal site. The answer, as with many questions is, it depends. For some clients, the best choice is to build a traditional, coupled Drupal website. For other clients, it makes sense to build a completely decoupled solution using Drupal as the backend. And for others, the best solution is somewhere in between. Many factors determine which is the best approach for a particular client and their situation.
One important factor in deciding what approach to take is to understand the needs and skills of the people that will use and maintain the system. The two main users to consider are the content creators and others that will work in the system daily and the developers that will build and maintain the system.
View Webinar Recording: Building Enterprise Websites with Drupal: Unleash Your Full Potential
Considering the Content Manager
For the content creators and content managers that work directly in the content management system (CMS), having an easy-to-use content admin system is key. Drupal has increasingly focused on this experience and has provided many features with this in mind. With traditional Drupal, content editors can quickly create pages leveraging the drag-and-drop capabilities of Layout Builder. Inline editing allows content editors to make quick changes to the content without diving deep into the content admin UI. And, content preview is available to review before publishing the content to the website.
All of this is also possible in a decoupled solution, but the developers must build and maintain this functionality or cobble a solution together from existing technologies. If the project requirements already require changes to Drupal's out-of-the-box functionality, building from scratch may be easier.
Considering the Development Team
The development team's skills are also an important consideration. If you have a team that has deep technical knowledge of a technology (or a desire to develop that knowledge), that can have an impact on the recommended approach. For instance, if your team has never themed a Drupal site before, but has experience with React, using a decoupled approach would fit nicely with the team's skills.
Like any framework, it takes time to learn how to theme Drupal sites. If you have a small team that is spread thin or maybe you don't have a team, a coupled approach using Layout Builder or Acquia's Site Studio could give your content editing team the flexibility it needs without requiring much help from a development team.
Considering the Digital Strategy
The overall digital strategy is an important factor to consider as well. Will the platform support a single site or is this a key piece to a multisite, multi-brand digital platform? Is Drupal the only platform involved, or is Drupal a part of a broader digital experience platform (DXP) that includes CRMs, Commerce platforms, a CDP, and other platforms? Whether working with Acquia, the open digital experience platform built on top of Drupal, or connecting into other tools—Drupal is designed to make these connections easy.
Drupal is a great platform to integrate with other platforms. Many integrations are easy to implement by installing a community module. Drupal provides a robust migration system that makes pulling data into Drupal easy to do. Drupal also makes it easy to pull data out of Drupal using REST APIs or GraphQL.
If you are only building one website with the platform and it is primarily for marketing your organization, a traditional Drupal build probably makes sense. The more systems you are integrating and the more channels you want to use the content in, the more sense it makes to build using a decoupled approach.
Considering the Requirements
The requirements are another important factor to consider. Requirements help us define the solution. Just as important as the requirements are how flexible the requirements are. Drupal provides lots of functionality out of the box. When you add the availability of more than 40,000 free community-contributed modules, Drupal can meet many requirements with very little effort.
As you define the requirements, you should compare them to what Drupal can do. And where there is a module that meets most, but not all, of the requirements, decide whether it is possible to change the requirements. The more Drupal satisfies the requirements that you would need to build yourself in a decoupled approach, the better the coupled Drupal approach makes sense. If you find that your requirements will require a lot of customization to Drupal, a progressively decoupled or even fully decoupled approach may make sense.
Considering the Budget and Timeline
Every project has budget and timeline constraints. If you are on a tight timeline (and budget), building a coupled Drupal platform is often a solid choice. Drupal provides so many out-of-the-box features that, with flexible requirements, you can build a website in a very short period of time. For instance, we were able to build a small Drupal site using Site Studio in just a few days. The more expansive your budget and timeline, the more options you have in approach.
The Versatility of Drupal
After you've done the analysis and come up with the best approach, understand that circumstances may change. And, regardless of the approach, because Drupal can handle any of the approaches in the spectrum, you can evolve your approach over time. Because Drupal has been built with an API-first approach, it allows you to change your approach from a coupled Drupal approach to a fully decoupled approach over time.
Here at Bounteous, our website was originally built with a coupled approach. However, we recently decided to refresh the site. Drupal has allowed us to decouple parts of the site that make sense to decouple but keep the other parts coupled. As needs dictate, we can continue to decouple only the parts that we need to.
Drupal is a versatile system that can be the centerpiece of your DXP. How you use it will depend on the factors above and others that you find important. Regardless of the approach you take, Drupal is versatile enough to change as your needs change in the future.

Contributing to Drupal is one of the most important things we can do as a part of the Drupal community. Considering that the platform is open source, contributions are essential to keep Drupal advancing. When it comes to contributions, there are a number of ways to get involved—and they don't all involve coding. I recently had the opportunity to contribute in the form of speaking at DrupalCon about a module our team rescued.
The Origins of Our DrupalCon Session
Our Drupal team has been working with the TB Mega Menu module since 2017. As we worked on various projects and tried to meet each client's different needs, we ended up making many updates and changes to the module. We eventually realized this module was no longer being maintained, so we applied for ownership and, ultimately, ended up rescuing the abandoned project.
We saw first-hand the community benefit that came from this project going from abandoned to rescued. Once we added our fixes and started updating the module, the community began using it again. Seeing the community jump right back in helped us to understand the value of contributing back to Drupal.
Encouraged by this new understanding of the importance of this contribution, we looked for a way to share that with the greater community. In a way, us sharing our story about contributing back to Drupal is another way to contribute to the Drupal community.
The Speaker Application Process
Since we wanted to share our experience of community contribution and demonstrate there are many different ways one can contribute, we decided to share our story at Drupal camps and DrupalCon. We first applied to Florida DrupalCamp and we did not get in. If something similar happens to you, it's important to not get discouraged. We took that "no" and let it drive us—we only worked harder when we applied to DrupalCon.
We spent a lot of time updating our proposal to DrupalCon. Our hard work and proposal revisions paid off, and we were rewarded with a "yes!" Some tips to keep in mind when working on your proposal.
Pick a Topic that Excites You
Pick a topic that you're excited about. If you're passionate about your topic, that will shine through in your proposal (and later on in your presentation). We were very excited about our topic and held it close to our hearts, which fueled our proposal development.
For our DrupalCon proposal, we took a step back and thought about how we could share this experience we were so passionate about, and how we could have our audience understand the importance of this contribution and get excited themselves.
Keep Your Proposal Direct and Concise
Make sure your proposal is direct and concise. It's always helpful to have other people take a look at your proposal and provide a fresh perspective. If you're able to, it's also beneficial to have someone with speaker proposal experience review.
Select a Catchy Title
Choose a title that's eye-catching and true to the content of your session. Of course, you want your title to create interest, but it's also important to make sure that your session's attendees are getting the content they expected when they chose to attend.
My Experience as a First-Time Speaker
Contributing to TB Mega Menu and presenting at DrupalCon were my first major experiences within the Drupal community. This year, DrupalCon was virtual, and it was a cool experience presenting online. As a first-time presenter, there were a few things I found comforting about presenting virtually. Personally, I felt less nervous because I didn't have to stand on stage and present to a crowd. I felt a bit more casual and comfortable in my own home. There was a chat and Q&A feature so I could see if the audience was engaged in my presentation. Overall, I enjoyed presenting virtually for my first speaker experience.
Co-presenting with my colleague Wade Stewart was another important element of this experience. I had never presented before at any conference, so having a co-presenter for my session helped to alleviate some of the nerves I experienced.
We did a lot of individual practice to get familiar with our own pieces of the story, and we also practiced frequently together to ensure we both felt comfortable and that we had a good flow. For anyone who is interested in speaking at a conference like DrupalCon but who might be hesitant or nervous to do it alone, I definitely recommend finding someone to co-present with. In my experience, it removed a lot of pressure and made the experience more fun.
Giving Back to the Drupal Community
It has been great as a relatively new member of both the Drupal community and Bounteous to be able to speak at DrupalCon and participate in TB Mega Menu. Both of these experiences have really helped me to appreciate and understand how important the community is around Drupal.
I am thankful that I was able to contribute via our module rescue and then contribute again in a non-code way by sharing the experience and speaking at DrupalCon. I encourage everyone to explore the ways that you can give back to the Drupal community! Contributors can earn credits for identifying or fixing problems, contributing code, or a host of other non-technical options like speaking at conferences.
In the latest version of Site Studio, Acquia has introduced a game-changing feature that is sure to challenge Drupal Core's Layout Builder as the premier go-to tool for site builders. Site Studio already has a superb component building and editing experience, but now users can add and edit components live on the page.
In this post, we'll go in-depth on this new feature, plus other recent updates to Site Studio.
Visual Page Builder in Acquia Site Studio
On previous iterations of Site Studio, users could edit existing components on the page live via the Page Editor, but the components had to already exist in the layout canvas field. This operated in a similar fashion to other Drupal page builder elements such as panels, layout builder, paragraphs, etc., and only is accessible through contextual links. If a user wanted to add a brand new component to the page, they had to add it via the node edit form. But now, all of that changes.
While the layout canvas is still accessible via the node edit form, content editors can completely assemble a page from the front end, providing an entirely new meaning to the layout canvas field concept. Other than page creation or administrative settings, content editors may have little need to open the node edit form when adding page content. Of course, this all depends on how your site's content types have been architected. Here is a brief tour of the new page builder experience:

When a user is logged in and on a page that utilizes Site Studio and a layout canvas, they will see a new Page Builder button on the admin toolbar.

Enabling page builder mode will allow users to add, edit, move, delete, duplicate, and/or save as component content. Users can also save the entire page layout.

As great as this new experience is, it's also helpful to see consistency in how new components or elements can be added via the left side, off-canvas components drawer, making it seamless. Users don't have to re-learn how to add components, but rather get an improved page building experience.

The component editor itself also behaves the same way whether users are using the page editor, visual page builder, or the layout canvas on the node edit form.
The visual page builder is included as a new submodule within Site Studio and has to be enabled before it can be used.
Pro Tip: Developers should also be aware that anytime you update Site Studio, enable new submodules, and/or create or alter components, it's important that you run the import and rebuild functions. This can be done from the Site Studio UI or via Drush commands. For additional information on how the visual page builder works, visit Acquia's Site Studio documentation.
Site Studio's new visual page builder provides a whole new meaning to "what you see is what you get." The page building experience for content editors has never been better or easier, and this new feature alone should be enough to convince you to use Site Studio on your next project.
Other Site Studio Highlights
While the addition of the Visual Page Builder is kind of a game-changer for Site Studio, the latest release also includes some other smaller but no less important features, including some accessibility enhancements, rel attribute support, and more.
Sync Batch Limit Overrides
On previous builds of Site Studio, admins were limited to importing 10 configuration items at a time via Site Studio Sync to reduce the amount of memory required. Acquia has now exposed a method allowing admins to override the default setting. By adding the following to a Drupal settings file, you can increase the number of configuration items that process per import batch:
$settings['sync_max_entity'] = 20;This is one of the few items of Site Studio that is controlled by a developer and must be updated in code. Users should also be aware that by increasing this value, more memory will be required and can lead to issues.
Rel Attribute Support
Acquia has also added support for the Rel attribute on the link element. This attribute defines the relationship between the linked resource and the current document. Previously, if users wanted to have Rel attribute options on links, they had to be added by a component builder. Now, when a link uses the type "URL" and the target is set to "New window," a group of checkboxes will automatically appear for the following options:
nofollow- prevents backlink endorsement, so that search engines don't pass page rank to the linked resource.noopener- prevents linked resources from getting partial access to the linking page, something that is otherwise exploitable by malicious websites.noreferrer- similar tonoopener(especially for older browsers), but also prevents the browser from sending the referring webpage's address.
The new Rel attribute can be found on the Link, container, slide item, and column elements. It should be noted for the SEO conscious, that the use of nofollow will stop search engines from passing page rank endorsements to the linked resource. This is often used in blog comments or forums, as these can be a source of spam or low-quality links.
Google and other search engines require nofollow to be added to sponsored links and advertisements. Additionally, the use of the No referrer toggle can affect analytics because it will report traffic as direct instead of as referred.
Nolink Token Support
One under-the-radar update from Acquia is the ability to use the token on Site Studio menu templates. For any experienced site builders, you probably know about the ability to use the token on menu links to render them as a heading, etc., and without a link attached. It's a great way to add sub-level menu headings.
On previous builds of Site Studio, users were unable to use the token as it would still render as an anchor tag with an empty href. In 6.5, using will result in the menu item rendering with a tag instead. Nothing needs to be done to start using the token, though, your menu styles may need to be updated to account for the usage of tags. Also to note, if a different HTML element has been specified in your Menu Template, that setting will take priority.
Accordion Accessibility Enhancements
Accessibility is a moving target. Keeping a site up-to-date with accessibility enhancements is one of the more important responsibilities we have and Site Studio is no exception.
In this version, Acquia has added some accessibility improvements to the Accordion element for the end-user. The header links will now have an aria-expanded attribute, which toggles between true and false when expanded and collapsed, respectively.
Accordion header links will now use aria-disabled="true" if the parent Accordion tabs container has the Collapsible setting toggled OFF. This is only applied when the item is expanded, to indicate to a screen reader that the panel cannot be collapsed manually.
When the panel is collapsed because a sibling accordion item is expanded, the aria-disabled attribute is removed. Accordion header links now have aria-disabled="true" permanently set if the accordion item has been disabled through Navigation link settings.
Bug Fixes and Other Improvements
The latest build of Site Studio also includes a bug fix that is related to sync package entity dependencies not being removed if they were no longer being used on the entity. Essentially, when a sync package contained entities that have had their dependencies updated, the sync package would contain both the original and the new dependency.
For example, if your component exists in a package, you then update that component's default image, both image files would be included in the sync package rather than just the latest one. Now the old dependencies should no longer appear in that sync package. This could also potentially reduce the size of sync packages in the case where multiple, deprecated dependencies were present.
Font Display Property Options
And last but not least, Acquia has now added a font-display property option to the Font library settings page. This CSS property, when used, will determine how a font face is displayed based on whether and when it is downloaded and ready to use. It is a very small feature update but a useful one; although, only developers really need to worry about implementing it.
Summary
As with any Drupal updates, it's recommended to fully test these new features and fixes (as applicable) on your site's development environment before deploying to production. You should also have a backup of any code or databases before upgrading. Version 6.5 of Site Studio is not backwards compatible.
With the addition of Visual Page Builder, Site Studio is just further cementing itself as an excellent component and page builder tool for Acquia-hosted Drupal applications. The more improvements they make, the harder it is to imagine building a site without it.
For additional information on Site Studio, check out some of our other posts:

In order to create great digital experiences, you need to first have a great team in place. If you're reading this, you've probably already come to the conclusion that you need a Drupal team, whether it's to build a brand new Drupal site or to maintain an existing site. We've broken down some of the challenges and solutions for you to consider when building your Drupal team.
Defining the Skills and Roles Your Team Needs
First, it's important to step back and understand all of the different skills and roles that you may need on your team, depending on what stage you're at in your Drupal process. A team that is building a Drupal site may look very different from a team that is maintaining a Drupal site.
To build a Drupal site, your team likely needs to include:
- Product Owner to gather the requirements for the site and determine what the site needs to do
- Experience Design to design the site
- DevOps to build the infrastructure to host the site
- Technical Architect to plan out the site build
- Developers to build the site
- Project Management to keep the project on track
- Quality Assurance to confirm the site works as intended
- Content Editor/Creator to build out the content for the site
Once the site is built, however, your team needed to run and maintain the site may need to include:
- Developers to maintain and enhance the site
- DevOps to keep the site up and running
- Content Editor/Maintainer to keep the content up-to-date
- Marketing to attract users to your site
- Analytics/Insights/SEO to understand how users are using your site and adjust the site accordingly
- Project Management to manage the team on a day-to-day basis
- Product Owner/Experience Design to plan out and design new features and functionality for the site
Not only can the needed roles change depending on whether you're building a site or maintaining it, but some of the skills required won't be needed at the same frequency. For example, for any reasonably sized site, you will need at least one full-time developer to maintain the code, fix bugs, and add enhancements. However, once the platform is built, the amount of DevOps tasks may not occupy someone full time.
So this then leads us to the question of: should you build your entire Drupal team in-house? Or should you outsource some of it—or even all of it?
Building Your Team: Hire In-House, Outsource, or Both?
The possible solutions fall on a spectrum and each has its own set of considerations.
Hire the Entire Team In-House
If your organization is large enough, there's a good chance you have the resources to hire an entire team.
First, map out the talent you already have available to you internally, and identify the gaps in skills that need to be filled. Then, before jumping immediately into recruiting for the specific roles outlined above, consider if you might be able to hire someone that is more of a generalist. For the skills that won't be needed often enough to keep someone busy full-time, can you find one person to wear several different hats? If so, can that person be effective enough at those different skills for your Drupal site to be successful?
After exploring your options, it's time to move into the recruiting and hiring process. Good Drupal talent can be hard to find, but it's out there! A good place to start is on LinkedIn, searching for people with Drupal capabilities that may be in or connected to your network. Networking in the community can be very helpful if you're looking for local talent: consider meetups, or local events like MidCamp in Chicago if the timing is right. There are also job sites that specifically call out Drupal talent, like jobs.drupal.org.
Hire An Agency That Already Has People With the Skills
If your organization is smaller and you don't have the resources to hire an entire team for building and maintaining your site, your best bet may be to work with an agency.
If you do not have an IT team, it might make more sense to host your site with a provider like Acquia rather than building a DevOps team to monitor and maintain the infrastructure. Even if you do have a knowledgeable IT staff, it may not make sense to use them for this if they are not used to working with the technologies needed to host a Drupal site.
By working with the right partner, you can rest assured that your site is in the hand of experts. When evaluating partners to work with, you’ll want to first make a list of the things that matter most to you. You probably want more than just a great website end result; more than likely, you also want to become smarter from the experience and retain knowledge, as well as have confidence that you’ll be able to maintain and grow the site.
Identifying what you want to get out of the experience besides the actual website will help guide you in choosing the type of company you want to work with. Some companies will focus solely on turning the website around quickly. Others, like Bounteous, focus on improving digital capabilities and maturity—while also delivering an excellent experience to your customers. If that entices you, look for partners that value co-innovation.
We also encourage you to choose a partner that contributes to Drupal. This will have a great impact on the Drupal community and, ultimately, improve the Drupal ecosystem.
Hire an Agency to Build the Site, Then Hire and/or Train Your Own People to Run & Maintain It
The perfect solution for your needs might be a mix of the first two options. Hiring an agency to do the build and then hiring and training your own people to maintain it will grant you the benefits of having experts build your site, and not having to hire an internal team for building that might then need to change once the build is done.
This option is also beneficial because once your partner of choice is finished with the site build, they can actually be a great resource in helping to hire the talent you need to maintain the site.
Your strategy can (and likely will) shift over time, so your approach to your Drupal project should reflect that. Even if your long-term desire is to do it all in-house, you can ease into that through evolving your approach over time. Some of our clients bring us in at the start to build the platform and create a strong foundation. Then they have us actually teach them Drupal and work alongside them as they learn. Ultimately, they end up taking over everything in-house.
Take the Long Road and Learn as You Go
Building a Drupal team can seem like a daunting and challenging process, but the good news is that you're never alone. Take time to consider the phases that occur after launching a site, a new site will need to do more than just expose information—what integrations are required, what will come next in terms of digital capabilities? Thinking about maintenance and growing your digital maturity may influence your hiring/staffing goals.
Rethinking the Replatform - Taking Advantage of Drupal’s Features and Flexibility
Get (or stay) involved with the Drupal and open source community. Involvement in the community means you will always be surrounded by individuals who are more than happy to answer any questions and provide guidance along the way. Learn from other people's experiences and stories and apply those learnings to your own decisions. And lastly, adapt and learn as you go!
Your great Drupal team is within reach—get out there and make it happen!
If you're reading this, you may have already noticed that we've recently given Bounteous.com a fresh coat of paint. What might be less obvious is that we also took this redesign as an opportunity to slowly begin decoupling the front end of our existing Drupal site. We've considered decoupling in the past but were unable to justify the effort for a full-scale overhaul of our front end given other competing responsibilities. So what changed this time?
Our initial design concepts implied a phased approach. There were effectively only two pages that featured a completely new design and also incorporated a number of new behaviors and animations not present on the existing site. For this first phase, the rest of the site would get a mostly cosmetic overhaul, applying updated global styles to better match the new design introduced elsewhere on the site.
This put us at a similar crossroads. We believed that leveraging a JavaScript framework would greatly benefit our ability to achieve the motion-based interactions implied by our ambitious new designs. But for this phase, introducing a JavaScript framework wasn't really necessary for the rest of the site. In the short term, the cost of decoupling the entire site would greatly delay our ability to ship what was essentially just two new pages. This conclusion led us to a question that in hindsight seems pretty obvious:
Could we start by only decoupling two pages on our existing site?
Initially, we didn't know. But as we started considering this project with the assumption that we could make this change only for these two new pages, it became the difference between taking this step now or continuing to kick a large-scale change to our front-end architecture down the road to some undetermined date.
We eventually landed on an iterative approach to decoupling Bounteous' existing Drupal site with Gatsby; starting with only two pages, but laying the groundwork for any page on the site to be rendered primarily by either React or Twig. What follows is a look at how we did it, what we learned, and what we think this means for the future of our site.
Upcoming Event - DrupalCon North America
An Iterative Approach To Decoupling Your Existing Drupal Site With Gatsby
One Site, Multiple Front Ends
For our JavaScript framework, we selected React, which we were technically already using in some minor ways on the existing site. While it would be possible to do this with a different framework, we found that the large React ecosystem would greatly accelerate our ability to achieve some of the motion-based interactions implied by our new designs. We ended up using both Framer Motion and react-lottie extensively, and they saved us quite a bit of time and effort.
While we had already decided that we'd be building additional React components in support of this new design concept, we also decided that we'd specifically be using Gatsby as our React framework of choice. Gatsby's plugin ecosystem greatly simplified the process of sourcing data from our existing Drupal CMS. Gatsby also opened up the possibility of statically generating portions of our site, which Bounteous.com was well suited for, given that most of our content changes infrequently.
Compared to a client-side approach to decoupling, server-side pre-rendering can have both SEO and performance benefits. As an added bonus, having these pages pre-rendered separately from Drupal also made it easier for React developers to contribute without ever having to set up a local Drupal environment.
Settling on these initial conclusions provided us with the following high-level architecture:

Drupal would be the CMS backend powering content for all of the pages on the site; both traditional CMS rendered pages, and pages rendered statically by the Gatsby build process. In the middle would be what we referred to as our 'front end globals.' These globals would be consumed by each front end and included shared styles, variables that serve as design tokens, along with full React components.
This structure allows us to take a progressive approach to introduce static content to our site. Initially, we'd only be building a small number of pages statically, but as we prove that this workflow can suit our site and our team, we could gradually shift where the line exists between the pre-built and dynamically built portions of our site.
Or alternatively, if we found that this approach didn't meet our needs, we could shift back to having Drupal render the content given that all of the data already exists in the CMS.
Front End Structure
After some consideration, we decided to take a monorepo style approach and have Gatsby, Drupal, and our front-end globals live in a single repository. Since this was a single domain and we had no concrete plans to distribute these components beyond Bounteous.com, we decided that a simplified repository would help streamline the process as we worked toward a tight timeline.
From the front-end perspective, this resulted in three main top-level directories in the repository: /fe-global, /drupal, and /gatsby. For this phase of the project, /fe-global exclusively contained Sass partials containing design tokens and global styles. Drupal and Gatsby would each selectively import from these partials as needed.
On the React side, we initially focused on building functional components with as little internal state as possible. This allowed us to prototype in the browser early, and also would allow us to provide data to these components from various contexts.
Regardless of if the data was being sourced from Gatsby's GraphQL API, directly from Drupal, or even hardcoded, the same component could be used. This also allowed us to use Storybook heavily during this phase of the project in order to get early feedback on these components before data was fully integrated.

On the Drupal side of things, we created new content types for each of our decoupled page templates. We also continued to use paragraphs to represent our components as we had been doing for existing content on the site.
The structure of data from the Paragraphs module initially doesn't seem like a natural fit for decoupled Drupal projects, but with gatsby-source-drupal and a few small utilities (which we'll talk about later), we found this data to be reasonable to deal with. In fact, it ended up giving us a high level of layout control, down to the ability to reorder components on the resulting static pages.
Considering that the majority of our content was still being rendered by Drupal, we still had our traditional Drupal theme. This theme incorporated the partials and tokens from our front-end globals alongside Drupal-specific styles, templates, and JavaScript.
Serving a Subset of Decoupled Pages
One of the very first things we had to prove out to ensure that this approach was feasible was serving a combination of static routes (pre-rendered by Gatsby) alongside dynamic routes handled by Drupal.
As part of our Gatsby build process, we are copying the 'public' directory which represents Gatsby's build asset, into the document root for our Drupal site. For the initial phase of this project, we were able to use a couple of very specific .htaccess rules to serve our two new static routes.
We knew this solution wouldn't scale long term as we introduced more content to our site. Ideally, we'd want to be able to create Decoupled content within Drupal, specify a path alias, and automatically have that route handled statically. We eventually found that we could achieve this via .htaccess as well.
Our rules take advantage of Drupal's URLs not having a "file" component to them. When we call createPages in gatsby-node.js with an alias like /services, gatsby creates that route as /services/index.html. The main .htaccess rule checks if /public//index.html exists and rewrites if it does.
This essentially means that for any request the Gatsby route 'wins' if there is a related file in the 'public' directory (/public/my-alias/index.html, for example,) and all other requests fall back to being handled by Drupal. This has the extra advantage of bypassing Drupal's bootstrap process for all of our static routes.
As focus shifted over to data integration, some adjustments were also necessary to configure the gatsby-source-drupal plugin to meet our needs. The gatsby-source-drupal plugin pulls data from Drupal's JSON:API endpoints and makes this data available to React components via Gatsby's GraphQL API. By default, the plugin imports all data from the source Drupal site. Since for this initial phase Gatsby would only be used to build a small subset of pages, most of this data was unnecessary and also would have the side effect of greatly increasing our build times.
As an initial attempt to solve this problem, we used Drupal's JSON:API Extras module to only expose the resources that our Gatsby build needed to depend on. This helped, but we still eventually needed to enable the file resource, which pretty much immediately sunk our build times.
Gatsby was now importing (and worse yet processing) local versions of years worth of images that we didn't need to support our new content. We eventually found that it was possible to configure gatsby-source-drupal to only import the files referenced by content that was necessary for our builds, but it required a combination of configuration options that wasn't completely obvious from the documentation.
The first step was to add the file resource as a disallowed link type:
// In your gatsby-config.js
module.exports = {
plugins: [
{
resolve: 'gatsby-source-drupal',
options: {
baseUrl: ,
// Disallow the full files endpoint
disallowedLinkTypes: ['self', 'describedby', 'file--file'],
},
},
],
}This alone would result in all files being ignored by the plugin. A little bit further on in the disallowed link types documentation is the following note:
When using includes in your JSON:API calls the included data will automatically become available to query, even if the link types are skipped using disallowedLinkTypes. This enables you to fetch only the data you need at build time, instead of all data of a certain entity type or bundle.
This essentially allows us to re-include specific files if they are referenced by other content. What makes this feature potentially easy to miss is the fact that it uses the plugin's filter option, which typically further restricts the data sourced from the plugin. The resulting configuration ended up looking like this:
// In your gatsby-config.js
module.exports = {
plugins: [
{
resolve: 'gatsby-source-drupal',
options: {
baseUrl: ,
/// Disallow the full files endpoint
disallowedLinkTypes: ['self', 'describedby', 'file--file'],
filters: {
// Use includes so only the files associated with our decoupled content
// types are included.
"paragraph--dhp_hero": "include=field_dhp_fg_img",
"paragraph--dhp_animation_cards": "include=field_dhpac_images",
"paragraph--featured_post": "include=field_dfp_bg_img",
},
},
},
],
}With this configuration, if a featured post paragraph is used on the homepage, any associated background images (field_dfp_bg_img) will be sourced by Gatsby as well.
Providing Drupal Data to Our React Components
So at this point, we have access to all of the necessary data, and also a set of functional components that aren't yet aware of Drupal's data. We also have content types that can use a number of different paragraph types, in any order. This is great from the perspective of layout flexibility, but less predictable from a data integration standpoint.
To help manage this mapping we created a custom React utility called paragraphsToComponents. Assuming that we have an existing GraphQL query that provides paragraph data to our template component, we could use it like this:
const HomePage = ({ data }) => {
const paragraphs =
data.nodeDecoupledHomePage.relationships.field_dhp_components
const paragraphComponents = useParagraphsToComponents(paragraphs)
return (
{paragraphComponents.map((paragraph, index) => {
return (
{paragraph.provider({
paragraph: paragraph,
index: index,
})}
)
})}
)
}As we'll see in a second, the utility returns an array of components that can be used to render the related paragraph data. In the template component's render method we iterate through this array and render these paragraphs in order. This allows us to correctly process paragraph data in any order, with little heavy lifting or redundant code in our template components.
The utility itself is defined as follows:
import AboutUsBannerProvider from "../components/paragraphs/provider/AboutUsBannerProvider"
import AnimationProvider from "../components/paragraphs/provider/AnimationProvider"
import CalloutProvider from "../components/paragraphs/provider/CalloutProvider"
// … Additional component imports ...
// The paragraphs above map to these components:
const componentMap = {
dhp_about_us_banner: AboutUsBannerProvider,
dhp_animation_cards: AnimationProvider,
dhp_callout: CalloutProvider,
// … Additional component mappings ...
}
const paragraphsToComponents = paragraphs => {
// Create a new array with paragraph data that also specifies the React component
// we'll use to render it.
const mappedParagraphs = paragraphs
// Add a component key that defines the component using the following
// naming convention: ParagraphTypeProvider
.map(paragraph => {
const componentType = paragraph.__typename.replace("paragraph__", "")
paragraph.provider = componentMap[componentType]
return paragraph
})
// Filter out paragraph types we don't yet have a mapped component for.
.filter(paragraph => {
return paragraph.provider !== undefined
})
return mappedParagraphs
}
export default paragraphsToComponentsThis assumes a particular naming convention for our components: ParagraphTypeProvider where 'ParagragraphType' matches the Paragraph Type name from Drupal.
As you can see in the example below, our Provider components only have one responsibility: providing the appropriate data from Drupal to our functional components.
import React from "react"
import Callout from "../../components/Callout/Callout"
import HeadlineDivider from "../../components/HeadlineDivider/HeadlineDivider"
import { graphql } from "gatsby"
const CalloutProvider = ({ paragraph }) => {
const heading = paragraph?.field_dhpc_heading?.processed
const body = paragraph?.field_dhpc_copy?.processed
const backgroundOption = paragraph.field_dhpc_bg_opts
if (backgroundOption === "background__waves") {
return
} else {
return
}
}
export default CalloutProvider
export const CalloutFragment = graphql'
fragment CalloutFragment on paragraph__dhp_callout {
id
field_dhpc_bg_opts
field_dhpc_callout_size
field_dhpc_copy {
processed
}
field_dhpc_heading {
processed
}
}
'We're also defining a GraphQL fragment for the data that is required for this component. This gives us a consistent definition of the necessary Callout Paragraph data that can be imported into any other component that needs it.
Getting to this point took a decent amount of time and effort, but once defined it became much easier to integrate future Paragraphs from Drupal by following this pattern.
Shared React Components
There also was an integration problem to solve going from React to Drupal. We needed to syndicate the same header and footer component used by Gatsby to our Drupal pages so that we could provide a consistent look and feel throughout the site, regardless of which front-end technology owned rendering that page. Thankfully, by ensuring that our React components were strictly presentational we were well suited to use these components in a different context.
We approached this by creating an "exports" subdirectory alongside the rest of our React components which contained an exportable version of the header and footer. These essentially functioned as provider components just as we saw with our Gatsby data integration. Initially, these exported components used pre-defined data since they didn't have access to Gatsby's GraphQL API. However, we eventually found a solution to export these components using the same data that is available to our Gatsby build.
As a first step, we created a separate Webpack configuration that used these two components as entry points, and placed the related bundles into a 'dist' directory in the Drupal theme.
On the Drupal side, we used the Component module to help ease this integration. As a simplified successor to the progressively decoupled blocks module, Component allows you to define configuration in a .yml file alongside your JavaScript in order to expose your component to Drupal. In the case of our navigation, we defined the following configuration:
name: Evolution Navbar
description: 'Evolution Navbar'
type: 'block'
js:
'dist/navbar.bundle.js' : {}
'dist/vendors~navbar.bundle.js': {}
dependencies:
- bounteous/react
template: 'evolutionnavbar.html'
form_configuration:
theme:
type: select
title: "Theme"
options:
'': 'Dark Theme'
'theme-light': 'Light Theme'
default_value: ''
Alongside the following template:
This manages to do quite a lot with a little. Based on this configuration, a new block will be created that uses our evolutionnavbar.html template and loads our component JavaScript and any dependencies as a library. It also exposes a configuration form which in this case allows you to specify a light or dark theme to be used when rendering the component. The values of any form configuration will be added to the template as data attributes, in this case making 'data-theme' available to our component.
With that in place, the code for the navbar React component that we'll be exporting is as follows:
import React from "react"
import ReactDOM from "react-dom"
import { MediaContextProvider } from "../../components/layouts/Media/Media"
import abstracts from "styles/abstracts.scss"
// Grab cached data from disk.
import NavigationProvider from "../../components/provider/menu/NavigationProvider"
import templateData from "../../../public/page-data/template/page-data.json"
const queryHash = templateData.staticQueryHashes[1]
const data = require('../../../public/page-data/sq/d/${queryHash}.json')
const drupalProvider = document.querySelector(".evolutionnavbar")
const config = drupalProvider.dataset
ReactDOM.render(
,
document.getElementById("evolution-navbar")
)First, we're importing cached menu data from our Gatsby build. This was inspired by the approach outlined in Exporting an embeddable React component from a Gatsby app using Webpack. Sourcing this from a cache using a query hash seems…fragile, but it has been reliable for our needs thus far. This assumes that the Gatsby build runs prior to the Drupal build, which already happened to be the case in this project.
Next, we're selecting the wrapping div in the DOM in order to access all of the data attributes provided by our Drupal block. This allows us to pass the theme option set in the instance of this block as a prop to our navigation component.
Finally, we mount the component into #evolution-navbar which is used in the template that was specified in our block configuration.
This approach could add some overhead as the number of components you're working with increases, but works nicely for our header and footer. It also allows us to easily configure different instances of the component block to be used on different sections of the site. We use this to swap between the dark and light themes of the header, and even specify if the form in our footer should be expanded or collapsed by default.
Looking Ahead
While we're happy with the progress made with this initial release, there is intentionally more evolution to come. We've been working on improving the content editing and deployment process introduced by this new workflow. These changes include configuring Gatsby live preview, and also making enhancements to the build hooks module to allow our content team to trigger Gatsby builds on demand.
As we've continued incorporating more content into our Gatsby build process, we've also run into some pain and confusion around the seemingly arbitrary divide between our React and Twig components. In addition to working to make this distinction clearer to our team, we've also been experimenting with solutions that allow our React and Twig components to be used side by side in more contexts, including syndicating markup and styles from Drupal to be used in Gatsby content as needed.
So far we think this iterative approach can be of benefit to others looking to transition the front end of their existing Drupal platform without requiring the commitment of a large-scale re-architecture.
Taking an iterative approach can instead make it possible to prove that decoupling has clear value and also ensure that changes to the development, content editing, and deployment process fit the needs of your team. We're excited to continue evolving Bounteous.com and hope that you'll follow along.
For even more on this topic, check out Episode #284 of the Talking Drupal Podcast - Iterative Approach to Decoupling and An Iterative Approach To Decoupling Your Existing Drupal Site With Gatsby at DrupalCon North America.
The contribution ecosystem is one of the most important reasons for Drupal's success. With over 45,000 modules available to enhance and extend Drupal's functionality, these contributions are critical to maintaining Drupal's status as an enterprise-class content management system.
Getting involved in the Drupal community is beneficial to all parties but can be intimidating, especially when it comes to committing code. It can be hard to know where to begin, or you may not necessarily have an idea for a new module. But that doesn't mean you can't get involved.
Drupal modules are built and maintained by members of the Drupal community. Sometimes, community members move on for a variety of reasons and the module becomes stale. That's what happened to the TB MegaMenu module, a project with over 30,000 installations at the end of 2020.
Rescuing TB MegaMenu
Mega Menus are a critical feature for many Bounteous projects. We selected TB MegaMenu for Wilson.com a few years ago because of the flexibility to power the site's extensive dropdown menus.

Unfortunately, in addition to a number of bugs and missing features, accessibility was not well implemented by the module at the time. We were able to provide some patches to address these issues; however, since the project was not actively maintained at the time, we had no way to update the module for the broader Drupal community.
We were in a tough spot because we needed the improvements to keep using the module, so we found ourselves providing these enhancements solely for our clients. That situation was a perfect opportunity for us to get involved in the Drupal contrib community, so we decided to apply for ownership of the module.
Taking Control of Maintainership for a Drupal Module
What does that process of taking over a module look like? Turns out it's pretty simple. Creating a new request in the appropriate issue queue gets the ball rolling, and once you are approved as the new owner, you gain access to the codebase and the module's landing page.
The first thing we had to decide after taking over ownership of the module was how to prioritize our time. Needless to say, TB MegaMenu is not anyone's first priority, and all contributors have to strike the right balance between putting time into open source projects and billable work.
So with two codebases to maintain, one for Drupal 7 and one for Drupal 8/9, we prioritized our work as follows:
- Fix the most critical bugs that were preventing upgrades and new installs
- Commit the accessibility enhancements we'd developed internally
- Apply for security coverage
- Publish a stable release for Drupal 8/9
- Continue to address bugs in the Drupal 7 version while prioritizing enhancements for Drupal 8/9
Maintaining Open Source Contributions
Let's face it: carving out time to contribute to open source contributions can be difficult—especially if your clients' projects are not relying on updates or enhancements to that work.
The availability of our Drupal developers at Bounteous fluctuates as team members move between projects, so we knew that our contributions to maintaining the TB Mega Menu module would naturally ebb and flow over time.
In light of that, we knew that we'd need to push ourselves a little bit to keep up with TB MegaMenu maintenance work, so we gave ourselves some parameters for getting stuff done:
- Established weekly "office hours" to prioritize issues and ongoing work
- Leveraged a Jira board to track bugs and progress
- Promoted our efforts internally to get other team members excited and drum up additional support
- Simplified onboarding for new contributors by creating dedicated local development environments for TB MegaMenu work
- Lowered the barrier by providing different ways to contribute other than code
Fortunately, the odds turned out to be in our favor—particularly during the last quarter of 2020, when a core team of contributors came together and gained considerable traction on moving the module forward. Giving back to the community is a core part of working at Bounteous, and contributing to open source modules is just one way we bring that to life.
Supporting Open Source Drupal - Come For the Code, Stay For the Community
Quick Wins When Reviving a Drupal Module
It doesn't take much to bring real value to a stale project right away. If you're considering rescuing a module, scan this list to get an idea of the time investment needed and consider how small changes can make a big difference. Here are some things we were able to do right off the bat to start reviving the module.
Better Communication to Developer Community
One of the first things we did was to update the module's homepage to let people know that the module had new maintainers. This was one of several efforts to restore "faith" in the module and reassure developers who might otherwise be deterred by the number of open issues and lack of recent commits to the module's codebase.

Test, Review, and Commit Patches
The TB issue queue had several instances of patches that had been posted but never tested and/or reviewed. Merging commits for issues that have already been patched is a great way to improve the module right out of the gate—without having to write any code yourself.
Clean Up the Queue
We evaluated and either closed or postponed open issues that were duplicates, not reproducible, were no longer applicable, or had already been addressed in another patch.
This can be time-consuming, and in the case of TB MegaMenu, there is still an enormous backlog of open issues going back years and years that we'll probably never get through. But on a smaller project, this kind of cleanup can go a long way to making the issues queue more manageable.
Identify the High-Priority Items
Inheriting a large number of bugs and feature requests dating back years (7+ in our case!) might seem overwhelming at first—even after cleaning up the queue. Fortunately, drupal.org forces every issue to be tagged with a priority level, which can be an invaluable tool for determining where to start.
Aside from noting the obvious urgency of critical and major issues, it can be helpful to also look at context and feedback from the community. Issues that have received a number of comments over time show recent activity probably warrants your attention more than one that was reported a while back.
Creating Documentation for Developers
TB MegaMenu's documentation was limited, so we created getting started guides for both the Drupal 7 and Drupal 8/9 versions of the module, following the Drupal.org guidelines, and posted links to them on the module's homepage. If it's easy to understand how to use the module, developers can much more quickly determine if it fits their project's needs.
Providing simple, concise, and accessible documentation can make the difference between hours of headaches and a smoother, more efficient working experience. Inevitably, our investment in documentation will yield a more popular module with a larger install base.
Bringing TB MegaMenu Back to Life
Most of these things can be done without too much effort, and they are a great way to start breathing life back into the project. Here's the fun part: shortly after we started work on TB MegaMenu, we noticed an uptick in activity in the issue queue. By pushing out new commits and simply responding to tickets, the community came back alive!
We started seeing new issues being reported, and new requests for support and features (not that we like bugs, but we do like being able to fix them!). All of those community members who are getting involved now are helping us to make the module better and could also be contributors in the future.
Looking Forward: Contributing to the Drupal community
Now that we have some momentum and are more comfortable with the process and the code, we have big plans for more work with TB MegaMenu. Some recent commits improve upon accessibility and coding standards, and we're getting ready to start a 2.x version of the Drupal 8/9 codebase which will simplify the front end. We've also applied for security coverage, which is a big step towards validating the module for use on some sites.
Contributing to the Drupal community is good for everyone. It benefits you as a developer because it gets you involved in the community, gives you ownership, and helps build your expertise. Of course, it also helps to strengthen the community of Drupal users and developers because our collective efforts translate to better modules. And finally, it's good for your brand—since your work will help to elevate your company's status in the Drupal community.
Are you aware of a module that needs some help? Here are some links to help you get involved:
Thank you to Andy Olson, Irene Dobbs, and Wade Stewart for the contributions to the TB MegaMenu module and their help on the blog!

With so many products and services available these days to assist with your website needs, it can be difficult to navigate all the options and determine the right solution for your business.
At Bounteous, we do a lot of work with Drupal and Acquia products and services. Over the past year, we've spent considerable time working with Site Studio, developing training materials for clients, creating resources, and working through various projects. Let us give you a brief tour of Site Studio and why it's perfect for your next project.
What Is Site Studio?
Site Studio, formerly known as Cohesion, is a Drupal product from Acquia that makes it easy to build a component-based website. Site Studio transfers the Front-End theming layer to the UI and gives content editors and marketing managers more control than ever over their sites. It provides a new site-building paradigm that's far more efficient than traditional builds.
The tools and features that come with Site Studio provide an excellent base to start with that allows client-side developers to contribute to a build from Day One. The low-code nature of Site Studio shields content editors from the Drupal backend and allows developers to focus on the overall content editing experience they're creating. It also provides your development team the ability to create elegant, performant, more powerful sites in half the time.
Let's break down the top points that contribute to the above philosophy.
Low-Code
Site Studio is designed to be low-code. This can mean a lot of things for different systems; however, in the context of Drupal, this is an important point to highlight.
Drupal inherently has its own hooks and other functions in place that make it a very powerful but also customizable CMS. However, to be able to use these ideas and functions correctly requires some prowess that a developer who has never touched a Drupal site will most likely not possess.
This is where the low-code nature of Site Studio really shines. New developers do not need to learn hooks, template suggestions, or any of the other Drupalisms that you will find on most sites. By layering Site Studio on top of Drupal, we now have a mechanism that takes care of the heavy lifting that we as developers use to write in custom functions. Site Studio may be low-code, but it is certainly not low on features.
Easily Extendable
Site Studio comes with a myriad of predefined components and styles thanks to the DX8 UI Kit. After initial setup, developers are immediately given access to over 50 different components consisting of sliders, cards, accordions, and more. While this is all great to have at the start of site-building, Site Studio takes it one step further.
Every single component that comes with Site Studio is extendable. Not only does this allow developers without previous Drupal experience to build rich editing experiences—but it also gives a noticeable jump start to most any component the developer is tasked to build.
Need to build a slider but the existing component is missing a field you need? No problem! Extend the existing slider and add your field. All of which takes minutes and no custom code to be written. Site Studio has a ton to offer out-of-the-box, but there is far more you can do with it.
Staying True to Drupal
There's an important synergy to highlight here. Site Studio comes with wonderful and easy-to-use features right out-of-the-box, which is one of the main draws to using it on any project. But at the end of the day, Site Studio is using Drupal as its backend—and we as developers need to be sure things are done correctly and the overall health of the application is kept at the forefront.
The beauty of Site Studio is how it uses features of Drupal developers love and simply extends them rather than rewriting them. By using these strengths that come with Drupal, there's essentially no more complexity in debugging, testing, or deploying sites that use Site Studio. This translates into a developing experience that all developers, both experienced and novice alike, can use together.
Starting With the Backbones of Site Studio
Composer, configuration management, and local environment: these are things a Site Studio implementation will not shake up too much from the stock Drupal setup we already know.
When getting a client resource up to speed, it's important to make sure that these fundamentals are understood and configured correctly from the beginning to ensure the developer is set up to succeed. Let's break down each of these points.
Site Studio - Composer
Composer is still behind the scenes managing all packages and modules just like a stock Drupal site. The only difference here is the inclusion of acquia/cohesion in the composer.json file.
However, for a developer working with Drupal and Composer for the first time, it can be a bit daunting to make a change to the project. The understanding of Composer's inner workings and how it relates to a Site Studio and Drupal implementation is crucial for any developer to contribute to a Site Studio project.
Site Studio - Local Environment
Again, no real changes here when developing with Site Studio. Something we have found that can greatly benefit any developer, whether it be internal or client-side, is to choose a single virtual environment scheme for all Site Studio implementations. Once a standardized system has been sanctioned, you can build custom tooling for said system.
This is a massive save when it comes to time constraints and debug headaches. When using Site Studio, there is a Drush command that updates all Site Studio templates and components. Manually running this one command may seem trivial on the surface—but when added to our automated tools for resetting a local environment, it proved to be one of those little things that was worth more than its weight in code.
Site Studio - Configuration Management
With Site Studio, this is probably the biggest change you will first notice. Just about every setting, component, and template in Site Studio is tracked in configuration. While this is a wonderful part of Drupal 8 that Site Studio utilizes well, it can get a bit confusing when trying to decipher exactly what these YAML files are doing when it comes to a pull request and working alongside other developers.
The best way to handle these config files is to pull down the branch of the pull request and import the config to be sure that everything is showing as expected and there are no errors on import.
What's New in Site Studio
Like with any Drupal Module, continuous development and improvements are essential in keeping your module relevant and in use. Since we first got our hands on Site Studio in early 2020, we've seen a ton of improvements. We started with version 5.7.9 and are now working with version 6.4.0. The following are some of the improvement highlights.
Component Field Repeaters
In version 6.3, Acquia added the Component field repeater feature to Site Studio. This is one of the most essential and important features added to date. Previously, repeater patterns were only available via the Site Studio Views Template builder. Think of this like a For Each loop, a control flow statement for traversing items in a collection.
Without the ability to repeat field items in components (a feature that is common in Drupal Site Building), we had to create a parent/child component relationship using dropzones. This method was okay and got the job done, but there were some limitations with the accordion components. Some of the issues with using this approach were that we could not limit which components could be added to a dropzone nor could we save a component as component content (more on that later).
The only other option was to create components with limited cardinality or item limits. That's okay in some cases, but when considering an accordion component or a carousel, users usually want unlimited. But now with field repeaters, that can be done directly on the component, making Site Studio even more powerful than before.
For example, to build a component using Site Studio's accordion elements, you no longer need to rely on the drop zone and separate components. Users can set a field repeater on the accordion item and repeat as needed. This simplifies the component building experience, making it even more intuitive.
Component Content Improvements
In the newest version of 6.4, Acquia adds two major improvements to component content. For those not familiar, component content is a saved component created on a page that allows users to reuse it on multiple pages but have a singular point of entry in order to update.
Previously, component content could only be created via a layout canvas field and saved from there. This is fine for instances where you create a component that you decide to reuse after the fact, but what about a component that you'd like to go through an approval process before it ever ends up on a page? Now, component content can be created directly from the list of component content which now matches a more standard entity behavior.
In addition to being able to save component content from the Component Content Manager, you can also now save components as component content when using a dropzone element. Previously, components using the dropzone element could not be saved as component content, thus limiting what you could actually save. This was challenging to deal with since, in order to create the effect of a repeating field, we had to rely on dropzones beyond their original intended scope. Now, any component can be saved as component content.
There are plenty of other improvements and fixes. It's clear that Acquia is committed to continuously improving Site Studio, and we would expect nothing less.
Why You Need It for Your Next Project
Creating Drupal websites with Site Studio has never been easier for the content editor or the developer. No matter their experience, anyone can contribute to a Site Studio project. With all the feature-rich aspects that are available today, as well as the ones to come in future updates, we can all see why Site Studio is an important shift into modern application and website development.
Gone are the days when there are hard lines in the sand between content editor and developer. Site Studio is a welcomed tool because it echoes the same mantra that Drupal and the community have had since its inception: let's build something together.
Want to learn more about Site Studio and what it can provide for your client solutions? Check out our article that takes a closer look at Site Studio as well as how we built a site in 10 days.
High-performing websites require thought and intentionality behind their design and implementation. A single web page today is composed of many requests that happen over the network. These requests could include the markup for the page you're looking at, CSS instructions for how the page should be styled, fonts, images, interactions with analytics tools, and much more.
A common method to improve performance for all those requests is to use a Content Delivery Network (CDN), which is now out-of-the-box on Acquia Cloud! But, how do you set it up? More importantly, why do we even use a CDN? Let's explore these questions and equip you with guidelines for how to set up Acquia Cloud Platform CDN on your own project, and articulate its importance.
Let's Start With How
Before we can get to the "why" of using a CDN, it would be helpful to have some vocabulary about what a CDN is and how it works.
Let's start with the concept of HTTP caching. The HTTP protocol has instructions that tell a browser it can cache a response for a period of time. There are a lot of configurations that vary in use across browsers and servers, but let's just focus on one of those instructions called the Cache-Control header. This header can tell a browser that it’s allowed to cache an HTTP response for a period of time.
Take an About page as an example. Say the server responds with a Cache-Control header with the value max-age=60,public. This tells the browser that it can cache the response for one minute. Here's a visual of what that looks like:

You can see that the second and third requests from that browser are cache hits; the requests never hit the server. Why? Because the browser was told it can cache the response for one minute.
This is great for that user. But, what about all the other users coming to the site? They won't get a cache hit. Introducing...the HTTP proxy cache! An HTTP proxy sits in between your browser and the server that the HTTP request is going to. By default, an HTTP proxy cache just lets HTTP requests pass back and forth between the browser and the server. These HTTP proxies are allowed to respect the cache rules of the HTTP protocol, hence why we call them proxy caches. So, imagine many users going to the site. Each one will have their own browser cache, but the proxy will have its own cache. Here's what that would look like:

In this instance, user one goes to the site and the request goes all the way to the server because the user's browser does not have a cache value yet, nor does the proxy cache. But, when user two goes to the site, even though the user doesn't have a browser cache yet, the proxy cache does. So, the request doesn't go all the way back to the server, it just goes to the proxy cache and the response is returned.
Now, imagine there are 1,000 distinct users going to the site all within that single minute, only the first request would go all the way back to the server. The rest of the requests would be served from the proxy cache.
Why are we talking about proxy caches? Because, in large part, that's what CDNs do; that's how they work, and when you're thinking about how Acquia Cloud Platform works, it's good to keep this in mind.
Why Use a CDN?
Why would you use a CDN with Acquia Cloud, especially knowing that it already comes with a proxy cache called Varnish? Doesn't that seem like it's just duplicating functionality? Not exactly, especially when you think about the geo problem.
The Geo Problem
You're not sitting in the same room as the server that rendered this blog post to you. You might be miles away from the server and network latency can have a big impact on how quickly the site responded. With Acquia Cloud, you have some flexibility over what geographic region your servers are in. Let's say that About page we talked about earlier in our example was hosted on servers on the east coast of the United States. If you also live on the East Coast of the United States, you're in luck. But, what if you're viewing that page from Kenya?

Your browser is going to wait for each request to the server (including the Varnish proxy cache) on the East Coast of the United States and back. The network latency in this case can have a critical impact on the site's perceived performance to the user.
Well, what if we could serve that content from a server closer to the user? That is to say, what if we had a network of servers that could serve this content and the user gets the content from the server closest to them? That would certainly help with the geo problem! Introducing...the Content Delivery Network! With a CDN like Acquia Cloud Platform CDN, your users will get content from a server closest to them (after caching rules are applied).

Other Benefits of a CDN
There are other benefits to a CDN besides addressing the geo problem. It can reduce the overall requests that hit your Acquia subscription, which might help you target a lower subscription level. It can help improve your site's performance under peak load.
Consider the fact that any request served from the CDN is a request that does not consume resources like memory or Central Processing Unit (CPU) on the application or database servers. There are also security benefits for some CDNs, which are worth investigating on a case-by-case basis to see if they apply to you.
How to Setup Acquia Cloud Platform CDN
Acquia Cloud Platform CDN comes with your Acquia Cloud Enterprise subscription, however, there are some steps to get it set up which we'll discuss here.
On the tech side, there are a few interesting points:
- It's supported by the Acquia Purge module, which means you can do active purging of expired content.
- It doesn't support customizations: it's not compatible with a custom Varnish config (VCL) and it really only responds to the Cache-Control and X-Drupal-Cache-Tags headers from Drupal (it’s a little more complicated than that, but that’s the basics).
- It's not compatible with other HTTP proxies in front or behind it.
- It uses Fastly under the hood.
- It's still in Beta as of the time of this writing, so your setup process may vary from what's laid out here.
Here are two useful documentation links if you'd like to read more:
And now, the moment you've been waiting for—the steps for setting up Platform CDN. Here are my personal notes; again, since Platform CDN is in beta this may change, here is what I'm recommending:
1. First, talk with the Acquia Account manager to confirm Platform CDN is available on the subscription.
2. Add all domains you want supported to all environments in Acquia.
3. Add SSL certificates on each environment, ensure those certificates cover all domains on their respective environment.
4. Create a Support ticket to enable Platform CDN, be sure to clearly outline the Application as it is named in Acquia, which Environments, and Domains you want supported.
5. At this point, expect some back-and-forth with Acquia support as you iron out details of the setup. For example, at this point, you may go through setup of the Purge module.
6. Once Acquia confirms it's set up on their side, verify the CDN is working (we'll talk through verification later).
7. Update your Domain Name System (DNS) records to a low Time to Live (TTL) so that if you switch over to Platform CDN and it doesn't work, you can quickly switch it back (optional).
8. Update your DNS records. This will make Platform CDN live.
9. Again, verify the CDN is working.
10. Last, update your DNS records to a higher TTL (optional).
The overall process may take some time. I would set expectations at 3-4 weeks to include time to do testing, roll out code changes, and coordinate the rollout with Acquia.
How Do You Verify It Works?
The last thing you want is to switch your DNS over to Platform CDN only to realize some configuration is wrong and your site is down. You can easily prevent this scenario by verifying it's set up correctly, and below we'll go through five things to check. You’ll want to wait to do these verification steps until after Acquia has confirmed the CDN is set up on their side.
1 - Verify SSL
First, verify SSL is set up correctly. Of the five verification checks I list here, this is the only one you can do prior to cutting over your DNS. To verify Secure Sockets Layer (SSL), you can start by verifying the SSL certificate on the server environment itself is correct. The way I do this is a bit of a roundabout, but it works.
Get the public IP of one of the load balancers using a tool like nslookup. The domain for it's usually a pattern like sitenamestg.prod.acquia-sites.com where sitename is the name of your subscription. Then, pick one of your custom domains and set it to that IP in your /etc/hosts file (this file may be located in a different place depending on your operating system). Here's an example walking through these steps:
First, get the IP of the load balancer:
$ nslookup examplestg.prod.acquia-sites.com Server: 127.0.0.1 Address: 127.0.0.1#53 Non-authoritative answer: Name: examplestg.prod.acquia-sites.com Address: 151.101.41.193
Now, we set your custom domain to this IP in your /etc/hosts:
$ vim /etc/hosts ... 151.101.41.193 stg.example.com
Finally, we can open up our browser and check that the SSL certificate is valid. Both Firefox and Chrome will show a padlock in the address bar.

If you're on Chrome, you can additionally check what IP address stg.example.com resolved to by looking at the headers of the request in the network tab:

Now, repeat these steps for each domain on each environment you set up. If you're planning a DNS cutover for a new site launch, you can even test the live domain with this tactic. For example, if you set up the domain "www.example.com" on your PROD environment, but you don't want DNS to point there yet, you can still set up the SSL certificate and verify it works using this method.
Last, remember to remove those entries from your /etc/hosts file!
2 - Verify DNS is Pointing to Fastly
This is an easy check, but at this point, it requires that you have updated your DNS records according to what Acquia support has noted in the setup instructions. Take each domain and verify it's pointing to the correct location using a tool like NsLookup.
$ nslookup stg.example.com Server: 127.0.0.1 Address: 127.0.0.1#53 Non-authoritative answer: stg.example.com canonical name = acquia.map.fastly.net. Name: acquia.map.fastly.net Address: 151.101.189.193
3 - Verify HTTP and HTTPS Ports Are Open
This is also an easy check. It may seem unnecessary, but doing this can give you assurance that at least the path on the network from your local computer to the destination ports are working OK. I love doing this because I know if it works, any issues I do run into are at least not related to firewall issues. There are a variety of port checking tools you can use, here we'll use Netcat (nc).
$ nc -z -w 1 151.101.189.193 80 $ echo $? 0
You can see the exit code was 0 which means it succeeded. Now, we'll check the HTTPS port.
$ nc -z -w 1 151.101.189.193 443 $ echo $? 0
4 - Verify You Get Cache Hits From the CDN
Let's say you think the CDN is set up and working correctly and the site comes up, how do you know you're getting cache hits from the CDN and not Varnish? That is, how do you know the request is being returned from the CDN instead of going all the way to the server environment and back? We can inspect the HTTP response headers from the server to tell us this. To do this, we'll use curl, though you can use any HTTP client that shows you the HTTP response headers.
$ curl -ksD /dev/stdout -o /dev/null "https://stg.example.com" ... cache-control: max-age=60, public x-cache: MISS, MISS x-cache-hits: 0 ...
You'll see the x-cache header had MISS, MISS. This means the request was a miss on the CDN and a miss on Varnish. More importantly, note that the x-cache-hits value is 0. This means Varnish has had no cache hits for this request. So, let's make that request again.
$ curl -ksD /dev/stdout -o /dev/null "https://stg.example.com" ... cache-control: max-age=60, public x-cache: MISS, HIT x-cache-hits: 1 ...
Great! We see a cache hit! But, that was a hit from Varnish. How do we know? Because the x-cache-hits header incremented by 1. The x-cache-hits header is controlled by Varnish, not the CDN. So, what we want to see is a request where that value does not increase. Let's make the request again.
$ curl -ksD /dev/stdout -o /dev/null "https://stg.example.com" x-cache: MISS, HIT x-cache-hits: 1
Great! We see the x-cache-hits stayed at 1. This means the result came back from the CDN, it didn't go to the server environment.
5 - Verify Browser Cache Is Working
If you've already passed the last four checks, you're in good shape. The CDN is working. However, you probably also want to check that your browser's cache is also working. It's an easy check to do, here is an example of how to check it in Firefox:

Here you see the network tab. The "Transferred" column will show "cached" if it was served from browser cache. Be sure to look at different asset types to make sure they are getting cached: HTML, JS, CSS, Fonts, Images.
What Are Good Cache Settings?
Now that you know how a CDN works, why you would use one, and how to set up Acquia Platform CDN, you might be wanting to dig deeper into tuning your cache settings. How do you know what good cache settings are?
First, it's important to understand that you don't simply cache a "page," you cache the resources that make up the page. A given page might comprise a variety of resources. Here's an example that I pulled that shows a breakdown of what types of resources make up the "page" by the size of each resource:

Resource: https://www.webpagetest.org/
You can see that over 95 percent of the size of the page is JS, CSS, Images, and Fonts which are all highly cacheable. By default with Drupal, those will be cached for 14 days! That's pretty good, and depending on your site, you may consider increasing or decreasing that value which you can find in the htaccess file.
The HTML on the other hand is far trickier. The HTML may be highly-static content like an About page that you don't expect to change very often. Maybe you're OK if it takes 24 hours for someone to see an updated version of the content; that's pretty great cacheability for HTML content. But, what if that HTML has pricing or inventory of a product? That’s not very static, so if you do let it be cached you don't want it to be cached very long. A user seeing the wrong price might result in an unhappy customer.
The setting for HTML caching in Drupal is set in Configuration > Development > Performance, under "Caching" you'll see a setting called "Browser and proxy cache maximum age." If you change this value, keep in mind that any HTTP cache (like a user's browser or a CDN) will keep the cache for the last time it read the value.
Here are some reasons for a high cache maximum age:
- You have the Purge module set up to actively purge expired content.
- Your content is highly static.
Here are some reasons for a low cache maximum age:
- You are not using the Purge module to actively purge expired content.
- Your content is highly dynamic.
There are even reasons for disabling cache in certain scenarios. For example, some content may be sensitive and you want to ensure no one has a copy of it, including the browser's cache (read this drupal.org issue for an example).
If you read around, you'll find recommendations that vary widely. Some recommendations are conservative around 1 to 60 minutes, and some are not, and say 6 to 12 hours. Unfortunately, it's difficult to make general recommendations about caching policies. The truth is, it depends. And, for complex sites, you're not making a policy for all content and all users—it may vary by user role or by type of content.
For example, you may want content pages to have a high-cache maximum age, but product pages have a low-cache maximum age. The policies will also depend on what other caching headers you are using, a key one being the Vary header. Ultimately, you'll need to put some thought and rigor into deciding on what policies best suit your needs.
It's worth repeating that high-performing websites require thought and intentionality behind their design and implementation, and cache settings are a fundamental aspect of high performance.
PHPStorm is one of our favorite Integrated Development Environments (IDE) for building Drupal sites. In addition to its outstanding ability to help any PHP developer's productivity, it offers several Drupal-specific time-saving tools—like the ability to handle code completion for hook declarations and applying Drupal coding standards.
Among the many tabs that border the PHPStorm IDE window is one that offers access to one of the hardest-working components of the Drupal ecosystem...the database!
Many developers only interface with the database via Drush commands, performing database backups, or moving content from the server to their local machine. Given the Drupal database is where all content and active configuration are stored, developers should feel comfortable leveraging the database as a research and diagnostic tool when developing solutions or debugging problems. The database can provide insight into how your data is flowing throughout the system, which can help when debugging errors or when working with a new module that modifies data before saving.
In this guide, we'll show you how to connect to your local Lando environment’s Drupal database from within PHPStorm. If you’re using another local environment like DrupalVM or DDEV, you can use the following steps as a guide for how you can connect these other environments.
Obligatory warning: After you connect to the database, you'll have access to modify or delete data, tables, or the entire database. Be sure you’re not working directly with a live/production database! We suggest using the database tool on a local copy of the database that can be restored if needed.
Step 1 - Allow Lando to Receive Incoming Database Connections
By default, Lando does not allow anything but the Lando app to connect to the database server, so we need to tell Lando that it’s OK for PHPStorm to connect. In the Lando configuration file (either the project-wide .lando.yml, or in the local overrides .lando.local.yml), add the following lines:
services:
database:
portforward: 3307When added to a basic .lando.yml recipe, the file will look like this:

This allows port forwarding on port 3307 to the host 'database', which is the default name of the database container in the drupal8 / drupal9 recipe in Lando. If your database hostname is different, update as needed.
Finally, for this step, rebuild the Lando environment with lando rebuild --yes.
Step 2 - Connect the Database in PHPStorm
Now that Lando has been rebuilt and is running, we can connect PHPStorm to the Drupal database. If it’s not already open, click the database tab to open the database pane.
In the database pane, click the + sign to add a new data source, select MySQL (or MariaDB).

In the new window that opens, enter the server information and credentials to connect:

Since we’re using the default values that come with the Lando drupal8 recipe, we’ve entered:
- Name - a name you want to call this in configuration
- Host - defaults to localhost, you should be able to leave it as is
- Port - 3307 (or the port you assigned in
.lando.yml) - User - drupal8 (or the database username you assigned)
- Password - drupal8 (or the password you assigned)
- Database - drupal8 (or the database name you assigned)
When you click "Test Connection" you should see a green checkmark to verify that it connected successfully.
So, now what?
Step 3 - Use the Database!
The database pane should show you a tree of the database tables in your Drupal database. When you connect to the database, a console tab will open up in the main editor window. You can also browse the data in a table by double-clicking on the table name in the database tab. In the image below, we’ve opened the table block_content and have the data as a table in the main editor window.

Why Use this Database Tool Over Others
The database tool within PHPStorm has most of the features of JetBrains’s DataGrip IDE. There are too many features to cover, but here are three of our favorites:
Feature 1 - Viewing the Data in a Table
This seems pretty mundane, but scanning through data tables can help you visually pick up patterns about your data. The column headers allow you to sort by one or more columns to help you review the data in the table. You can also drag to rearrange the columns to make viewing the data easier for your task.
Feature 2 - Finding Data in a Table
When you need to find a specific string in a table, you can write a query by hand or you could use some of the built-in tools to make finding the string much easier. When you’re viewing a table, you can search all rows and columns by simply pressing Cmd+F or Ctrl+F. A magical search form will appear:

As you start typing, data cells with your search string will be highlighted. You can also check the "Filter rows" box to only show the rows that have your search string in them:

There are also options to search with case-sensitivity or with regular expressions, which can help you find all of the data that you’re looking for.
Feature 3 - Finding Data ANYWHERE!
This is a great tool to use when you know what you're looking for, but you aren’t sure where to find it. You no longer have to navigate a huge haystack of the SQL export text file to look for your needle!
In the database tab, right-click on the drupal8 database and pick "Full-Text Search...":

In the new window that opens, you can enter your search term and press Search:

PHPStorm will open the "Find" tab and show you how many matches were found in the tables of your database:

Delivering Great Digital Platforms
PHPStorm is a true workhorse of Drupal development. It allows talented people to be more productive in their efforts to create amazing features for Drupal and awesome digital experiences for users. The built-in suite of tools for PHPStorm—especially the database tools—makes this IDE my favorite when it comes to delivering great digital platforms for our clients at Bounteous.

Moving between hosting providers is never an easy task, but it can be done in a way that doesn’t have to be painful. One of our clients recently recognized the value of a hosting provider like Acquia. We were tasked with moving their site from custom AWS hosting to the Acquia Cloud Platform.
Acquia is the only Drupal hosting platform that's built for Drupal developers by Drupal developers. Acquia Cloud Platform is also the only web hosting solution for Drupal designed to scale to meet the demands of enterprise-class business challenges. With Drupal managed hosting from Acquia, you can create, scale, and manage your digital experiences knowing you’re leveraging the best that Drupal has to offer.
Acquia Cloud Platform provides secure and compliant web hosting for Drupal that delivers everything your teams need to build and manage Drupal-based digital experiences, including fully managed Drupal hosting, robust development tools, enterprise-grade security, and world-class support.
When migrating your site to a new platform, we want to ensure we’re still following best practices. There are many caveats to moving websites between hosting providers that can arise. We will discuss a few common ones throughout this article; however, every situation is unique. This means that your migration should be well documented, predictable, and repeatable. You should expect to perform the steps multiple times as these issues are uncovered and resolved. If we follow best practices and develop iteratively, we can prevent problems from making it to our live site.
Codebase
Our first step is to evaluate the codebase and make sure it is following best practices for Drupal development. This includes things like ensuring we are properly using version control, dependency management, and the config system. Most Drupal 8 sites should already be using these basic concepts, but this is a great point to perform some basic checks.
Next, we want to prepare the codebase to take advantage of all of Acquia Cloud Platform’s features. At the very least, we will want the Acquia Connector module which will allow our site to send metrics and other data to the Acquia subscription. This gives us access to tools like Insights and also helps Acquia maximize uptime. Another module we want to install is Acquia Purge for clearing varnish as well as the Cloud Platform CDN.
Once our code is ready, we need to get the code into Acquia’s repository so that we can deploy it to our new pre-production environment. This is a great opportunity to evaluate our CI/CD pipeline and make adjustments that aligned us with best practices. Fortunately, this project was already based on Acquia’s Build and Launch Tool (BLT), which gave us a plethora of commands to easily plug into our CI system. Using BLT also meant pushing the code was simple as changing the git.remotes configuration setting and running the artifact:deploy command.
Database
With our codebase in place, it’s time to get the fun started and transfer the database to the new environment. Using our friendly neighborhood Drush CLI Tool, backing up and restoring the database is extremely easy. To use Drush, we need to download aliases that are conveniently provided under the credentials tab within our Acquia account settings. The aliases are simply dropped into the drush/sites directory within our codebase.
To create a backup of the database we use the following command:
drush @client_legacy.prod sql:dump \
--result-file /tmp/client.sql --gzip \
--structure-tables-list="watchdog,cache_*,search_api_db_*,migrate_message_*"The results-file parameter tells Drush to store the file in a consistent place. This helps us maintain that predictability and consistency that is so crucial to our success. We also want to make sure we’re passing the gzip flag to compress the resulting backup file. It is important to note that this flag will add .gz to the end of your results-file path. Thus our resulting backup is actually located at /tmp/client.sql.gz.
The structured-tables-list option tells Drush to skip backing up the data for any tables matching the list. In the case of Drupal, we can safely ignore any cache as well as any module-specific tables that are generated dynamically or do not need to be preserved. This is extremely helpful in cutting down on database backup sizes.
Once the database backup has been created, we need to transfer it to the Acquia server. There are many ways to accomplish this, and my preference is to use sftp or scp. This is also a good point to take some notes on how long the transfer takes!
sftp [email protected]
sftp> get /tmp/client.sql.gz
# /tmp/client.sql.gz. 100% 500MB 4.2MB/s 02:00
sftp [email protected]
sftp> put client.sql.gz
# /tmp/client.sql.gz. 100% 500MB 2.1MB/s 04:00Our last step with the database is to import it into the Acquia site. One significant problem with this migration in particular was that the client’s database backup was roughly 2GB when uncompressed. Importing a larger database can present many problems such as the server running out of resources or the ssh connection timing out. Our solution for these issues was to run the import process as a fork and monitor the server until the import finished. To minimize the problem surface, we ran each command in an atomic way—avoiding unix pipes and logic where possible. This made our lives easier as we debugged the issue we encountered.
The commands we ran to import the database were as follows:
drush @client.prod ssh --ssh-options="-o ServerAliveInterval=60"# SSH into acquia server
cd ~ # Go to default upload location
rm -f client.sql # Remove any existing unzipped backups
gunzip client.sql.gz # Unzip our backup
cd /var/www/html/client.prod # Navigate back to our codebase.
drush sql-drop # Delete any existing
drush sqlc < ~/client.sql & # Import the database
free -h; ps -aux; top; # etc... Wait for database import to completeAt this point, we should be able to visit our temporary Acquia production URL and see a version of our site without any images.
Files
The next step in the migration is to sync the files which is easily achievable via the Drush rsync command. However, to keep in the spirit of optimization, we grabbed the rsync command executed by Drush and added a couple of options to make it more performant. This was especially helpful as the client had dozens of gigs worth of files.
The rsync command we used to sync the files were as follows:
rsync -e 'ssh ' -akzv --ignore-existing \
--exclude "styles" --stats --progress \
/efsmount/client.com/files/ \
[email protected]:/var/www/html/client.prod/docroot/sites/default/filesThe ignore-existing flag tells rsync skip copying files that already exist, which is helpful if your files tend not to be changed. We also want to exclude the styles directory as it can be dynamically generated (similar to cache tables).
Test and Launch!
Now that you have your complete site copied over, you can begin testing and validate that the site was properly copied. As issues are uncovered in QA and UAT, you will likely want to recopy the database and files to your Acquia Cloud Platform. Good thing we clearly documented our steps! Client data constantly changes and we want to do our best to ensure the success of our migration.
Once your site is stable and has been thoroughly tested on Acquia, it’s time to launch! Using the timings from our notes we can work with the client to schedule a maintenance period. It’s during this period that we will perform one final migration before cutting over our DNS. On launch day, we review our documentation with the entire team to ensure all members of the team (including the client) are on the same page.
As the work begins, you should be able to copy and paste all commands that you need to run and easily notify your team as you progress through the steps. Once your migration is complete, all that's left is to flip the DNS and decommission our old servers. Congratulations on your new Acquia Cloud Platform site!

Normally, being asked to build a component-rich website in 10 days might feel like a tall task that requires a superhero effort from all parties involved. But with Acquia’s Site Studio, formerly Cohesion, that’s exactly what we did.
There were no panic attacks and while we might look like superheroes, it didn’t require a superhero effort. Working alongside Marketing and Experience Design (XD), we took the requirements for a component-driven, single-page site and built it in a little over a week with ease.
What We Needed
Here at Bounteous, specifically within the Drupal Practice, we’ve spent a lot of time and effort learning about Site Studio. We completed the Early Adopter Program, we’ve earned certifications, and we’ve even written about it. It was time to put Site Studio to the test and our own Co-Innovation initiative was the perfect candidate for it.
We needed a single landing page site, one that would be a rich, component-driven page that was also elegant, bold, and looked great on any device. We needed a webform that would drive visitors to download our Co-Innovation Manifesto along with all the other behind-the-scenes elements involved with a build. And, it needed to be built in 10 days to coincide with a webinar that was being hosted by our CEO, Keith Schwartz.
Building a site in 10 days should not feel like a big deal, but to do it right, you need Marketing, XD, and Development to come together quickly to provide an actionable plan, provide design direction, and architect it. But, we are always up for a challenge.
How We Did It
So, how did we build a component-rich website in 10 days? The easy answer is that Bounteous is awesome and that’s just how we roll. We’re experts at what we do and there’s no challenge we can’t meet. But a more specific answer is, we used a combination of Drupal, Acquia Site Studio, and UI Kit to complete our project in such a short timeline.
We met with Marketing, where they outlined the requirements, which were to launch a landing page to coincide with a webinar. But how could we pull this off? We were all immediately on the same page: Site Studio. This gave Bounteous and the Drupal Team a great opportunity to finally put Site Studio’s promises to the test.
In addition to using Site Studio, we also suggested Acquia’s UI Kit. UI Kit was designed and built to accelerate the design and development process of a component-driven website. It provided us with the ability to build a Drupal site at scale, fast and efficiently.
Besides saving significant time on the build, another benefit of UI Kit was that marketing was able to view demos of each component, allowing them to quickly and easily select the elements they wanted us to use.
Not only that, but UI Kit provides templates using Sketch, an app that allows for rapid prototyping and collaboration. All we had to do was apply our color palette and typography to keep our brand consistent with our other digital properties. We even made a few structural and functional tweaks with ease to make the site shine. This made our conceive phase super fast, efficient, and it set everyone's expectations about how the site would behave once it was assembled and in the browser.
For the build, we quickly spun up a new Drupal site on our Acquia Site Factory instance. We configured our site based on Drupal standards. We installed Site Studio, imported UI Kit, and started building. From there, all that was needed was for us to add our color palette and typography. Next, we took advantage of Site Studio's ability to easily update and adjust components to fit within the Bounteous style guide.
There was no backend coding needed. This led to faster deployment and put the site into the hands of our stakeholders faster than ever before. It was just that easy. Once everything was in our production environment, we added content and published it. All in ten days, with plenty of QA time to spare.
Easy Building & Theming with Acquia’s Site Studio
As we use it more and more, Acquia’s Site Studio continues to be an exciting product; one that lives up to the hype. Site Studio makes the process of building and theming sites from start to finish smooth and easy. I am personally excited to continue to push the boundaries of what can be accomplished with Site Studio and the projects that it will benefit. And as for the Co-Innovation site, we have plans to expand it even further.
Pages
About Drupal Sun
Drupal Sun is an Evolving Web project. It allows you to:
- Do full-text search on all the articles in Drupal Planet (thanks to Apache Solr)
- Facet based on tags, author, or feed
- Flip through articles quickly (with j/k or arrow keys) to find what you're interested in
- View the entire article text inline, or in the context of the site where it was created
See the blog post at Evolving Web